

















「統計」とは
品質管理活動の中で、統計的方法を用いてデータの収集や解析を行い、基準や標準を決定していく活動を、統計的品質管理(Statistical Quality Control; SQC)といいます。統計学に裏付けられた、データの収集方法および解析手法を活用して品質管理を進めていくことが重要です。
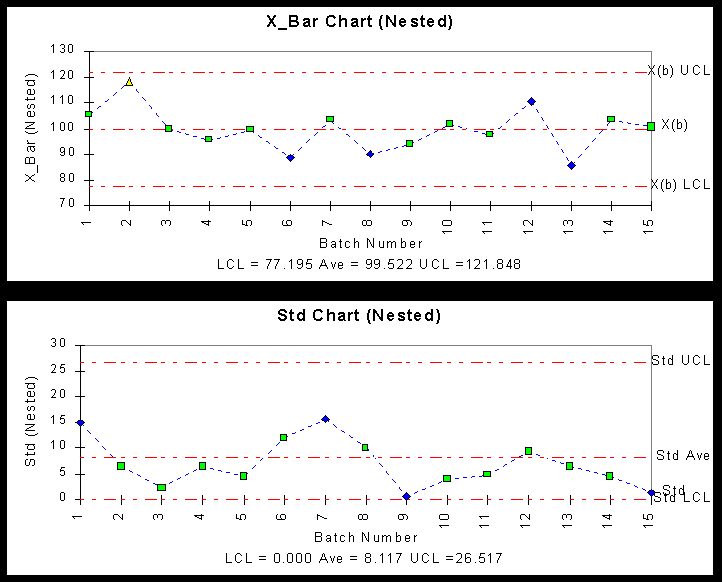
Xバー管理図
「統計」の意味は「統べて計る」ことです。「統べる」は、「多くのものを一つにまとめる」という意味で、「計る」は「ある基準をもとにして物の度合いを調べる」という意味です。
つまり、「多くのものを一つにまとめ、ある基準をもとにして物の度合いを調べる」ということになります。
「統計」は英語で「statistics」と書き、「国家(state)」、「状態(status)」と同じ語源のラテン語に由来します。
統計的品質管理の歴史
品質管理の歴史は、製造工場の品質を管理する手段に、管理図や抜取検査といったSQCの方法を用いたことから始まります。
このSQCが発展して、製品やサービスの製造段階だけでなく、アフターサービスまでの全工程で品質管理を行うために、サービス部門や管理部門も含む組織全体として統一した品質管理を全社的に行うようになりました。
この活動を総合的品質管理(Total Quality Control;TQC)といい、その後TQM(Total Quality Management)へと呼称が変わります。
現在、SQCという用語は、つぎの2つの意味で使われています。
①TQM全体の中で、統計的方法を利用した活動の部分
②現在のTQMと対比して、統計的方法だけを重視した初期の品質管理
統計的手法の目的
統計的方法を品質管理に利用する大きな目的は、作業中におこるデータの変動を、「偶然の変動」か「偶然でない変動」かに区別し、変動しているデータから、何らかの規則性を見つけ出すことです。
たとえば、製造された製品の重量に0.5グラムのバラツキがあった場合、統計的手法を用いることで、そのバラツキは偶然なのか、あるいは何らかの異常で生じるのかを知ることができます。
データ収集の場面でも統計的方法が利用され、数学的に裏付けされた統計理論を使つて、誤差の見積もりや、設定した誤差の範囲で結論を出すための収集すべきデータ数を検討することができます。
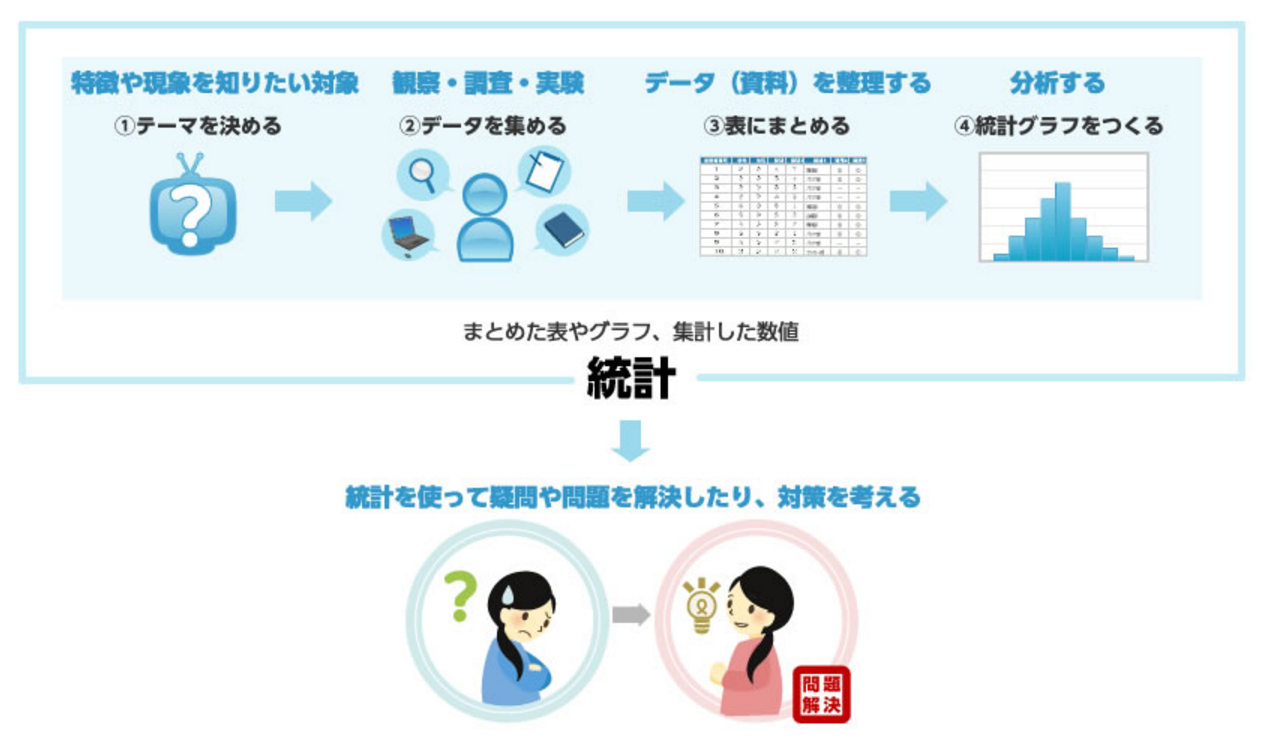
統計的手法の種類
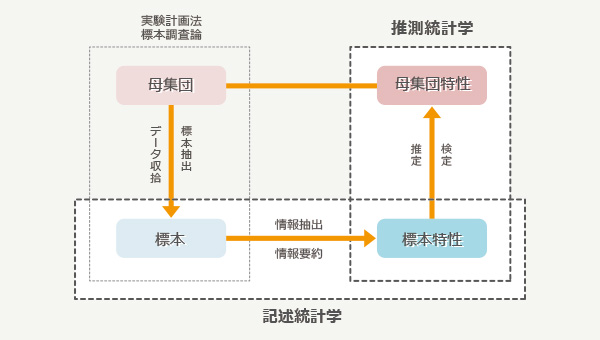
統計的手法には記述統計推測統計および実験計画があります。
記述統計
記述統計は、収集したデータの統計量(平均、分散など)を計算して分布を明らかにすることにより、データの示す傾向や性質を知るものです。
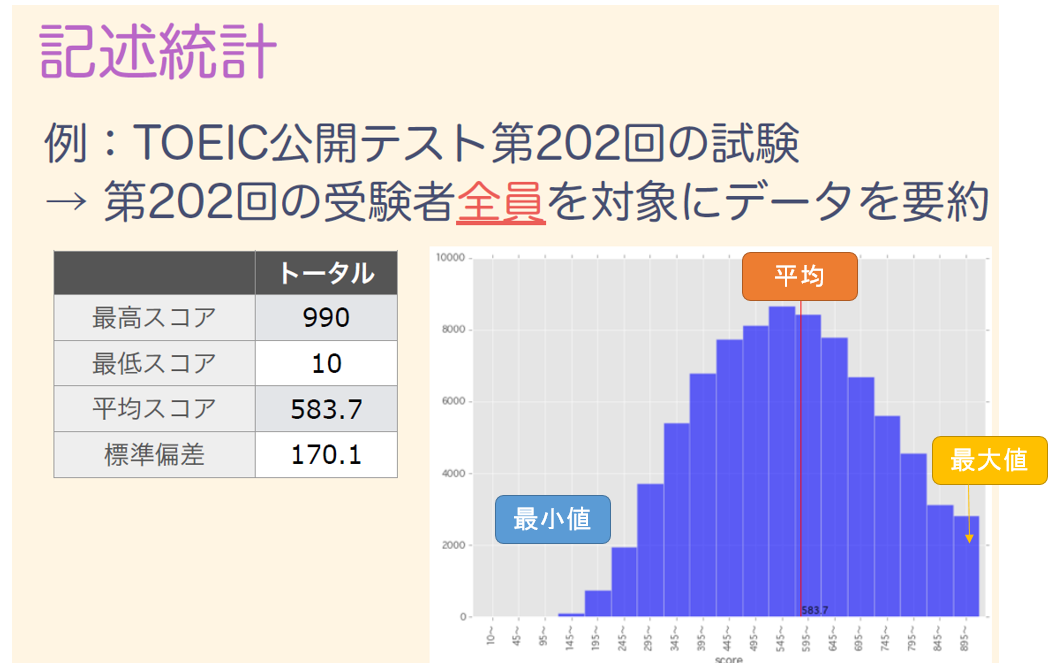
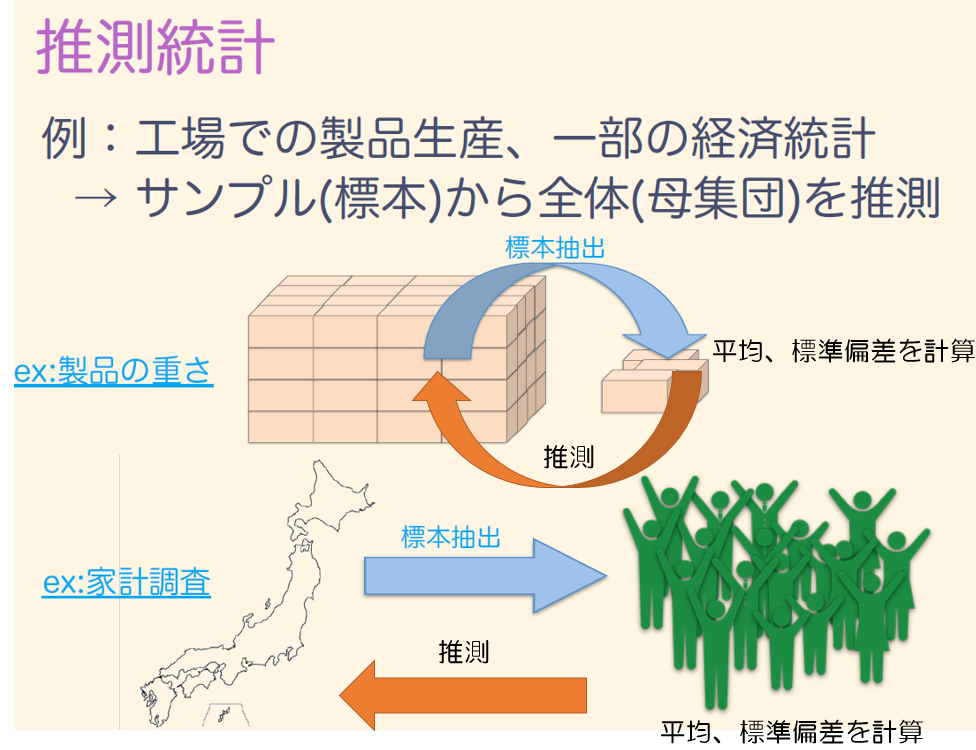
推測統計
推測統計は、採取したデータ(標本やサンプルとも呼ぶ)から母集団(全体のこと)の性質を確率統計的に推測するものです。
通常、時間やコストの関係で全数検査は無理なので、推測統計が用いられます。
統計的手法 体系
データーのまとめ方
統計的方法を用いてデータを処理する場合には、まず、対象としているデータが、どのような性質のものかを把握し、データから平均値や標準偏差などを計算して要約された情報を読み取ります。これらの計算された数値を統計量と呼んでいます。
データの種類
データは、身長や体重のように数値で表現される数値データと、性別のように文字で表現される言語データの2つに大別されます。統計的方法の対象となるのは、
数値データです。数値データは、さらに、つぎの3つに分けることができます。

計量値:
重さや時間など「測る」ことで得られるデータです。測定器具の精度によって小数点以下何桁でも測定でき、連続しているデータです。
無限に連続する値であり、重さ、長さ、時間、寿命、速度、温度、電流、音量など測定器を用いて計測される値です。
測定精度が高度であればあるほど無限の桁数を取ることができますので、実際に得られる値は何らかの制限により丸められた値となります。
真値を知っているのは神様だけであり、人間が知ることができるのは「真値と推定される値」です。

計数値:
不良品数や事故数など「数える」ことで得られるデータです。1個、2個と数え、1と2の間の値は存在しない離散的なデータです。
離散的な値しか取り得ない値であり、例えば、商品の価格、一日の売上、故障回数、不良品数など通常は1個、2個、3個、・・・と通常は数えられるものが多いです。
誤解しやすいポイントですが、計数値は自然数(1, 2, 3, …)である必要はなく、測定精度に依存しない値のことです。
計数値は離散的な値であるため、例えば 1.5, 2.5, 3.5, … というように小数点以下をとる離散値ということもあり得ますが、適用事例は少ないでしょう。
例えば、「一か月あたりの売上」であれば最小単位は1円であり厳密には離散値であると言えますが、実際のデータは数百万円オーダーとなる場合であれば、正規分布に近似しても誤差は十分小さいと考えることができるのです。

順位値:
1位、2位といった順位のように「比べる」ことで得られるデータです。官能検査やアンケート調査の場面で多く見られます。

基本統計量
データの集まりはいくつかの数値に要約することができる。このときに用いられるのが基本統計量である。統計量とはデータにもとづいて計算された平均値などの数値のことで、つぎの3つに大別される。
分布の中心位置を示す統計量としては、平均値と中央値がある。また、ひろがりを示す統計
量としては、範囲、偏差平方和、分散、標準偏差がある。さらに、分布の形を示す統計量としては、歪度、尖度がある。
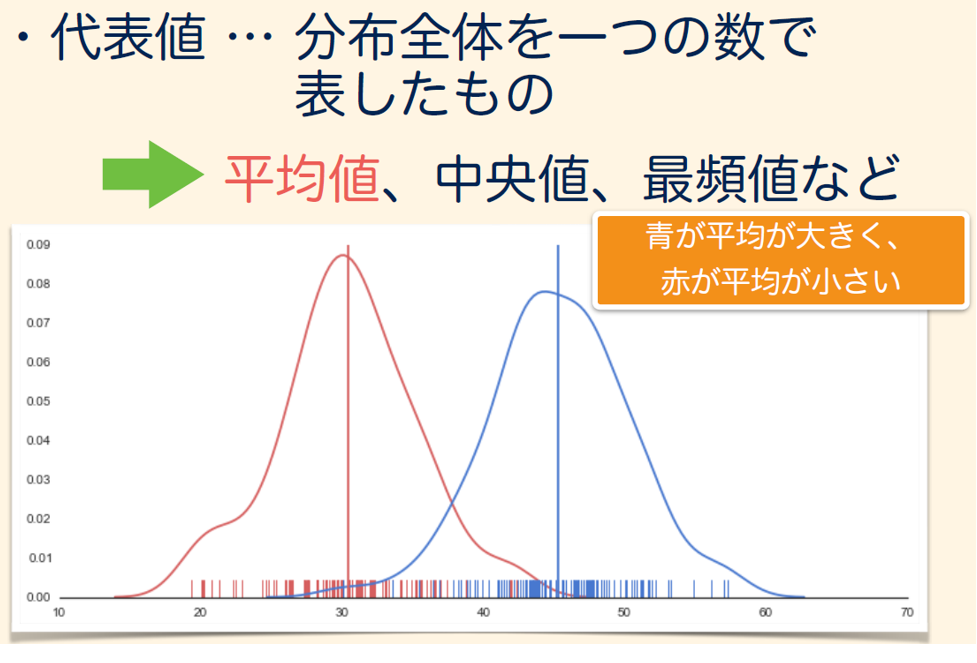
分布の中心位置を示す統計量:代表値
グループの「ふつう」あるいは「標準」を表す数値を代表値と呼びます。一番よく使われるのが平均です。
ほかに代表値には中央値、最頻値と呼ばれるものがあります。
平均値の求め方
n個のデータX1,X2、Xn‥があるときに,これらのデータの平均値はつぎのように計算される。
平均値はXという記号を使うのが一般的である。
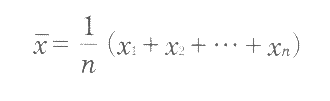
イラストサンプル例:

中央値の求め方
データを数値の小さい順(あるいは大きい順)に並べたときに、真ん中の順位にくるデータの値を中央値(メディアン)という。
例1:
14、12、10、19、16の5個のデータがあるときは、小さい順に並べ替えると、10、12、14、16、19となるから、中央値は14である。
例2:
14、12、10、19、16、18の6個のデータがあるとき、小さい順に並べ替えると、10、12、14、16、18、19となるから、中央に位置する2個の値(14と16)の平均値である15を中央値とする。

データの特徴を表すのが代表値
集めたデータの特徴を数値で表そうとするとき、その数値を代表値とよぶ。
代表値には、つぎの5つがある。代表値を簡単な例で求めてみよう。
①最小値(minimum) ②最大値(maximum) ③平均値(average)
④中央値(median ; メディアン)、⑤最頻度(mode;モード)
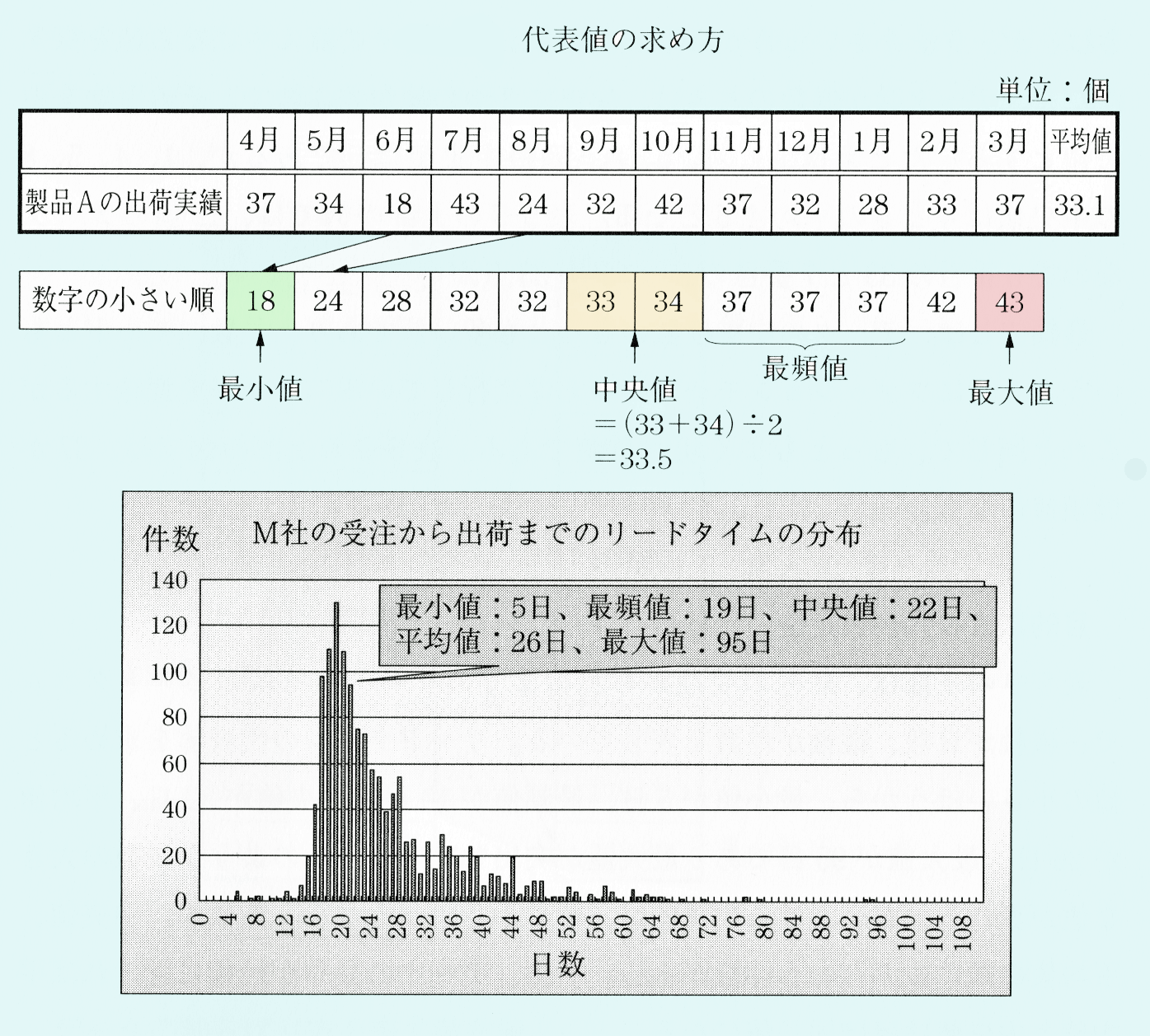
代表値の求め方
上表の上部は、製品Aの月別出荷実績である。出荷実績を数字の小さい順に並べた下側の表より、最小値の18個と最大値の43個は、すぐに読み取れる。
平均値は、個々の値を足し合わせて、その個数で割ったものなので、計算すると33.1になる。
出荷実績の平均値=18+24+28+32+32+33+34+37+37+37+42+43÷12=33.1
中央値とは、その値より大きい観測値のデータ数と小さい観測値のデータ数が同じになる値であり、順位的な意味での中心を意味する。中央値を求めるときは、データを小さいほうから順に並べなおして、その真ん中になる値を探す。
ただし、データ数が偶数のときは、中央に2つの値が並ぶので、その平均を中央値とする。たとえば、1、4、5、8、10の中央値は5であるが、1、4、5、8の中央値は4と5の平均4.5となる。上表の上部の例では、12個のデータなので6番目の33と7番目の34の平均33.5が中央値になる。
最頻値とは、データの中で度数のもっとも多い値であり、並数、モードともいう。一般にフアツションモードといえば流行しているスタイルを意味するが、これと同じで、もっともよく現れる値である。上表の上部の例では、37が最頻値になる。
目的により代表値を使い分ける
上表の下部は、M社の受注から出荷までのリードタイムのヒストグラムで、横軸が日数、縦軸が件数を表している。リードタイムの代表値を求めると、値の小さいほうから、最小値が5日、最頻値が19日、中央値が22日、平均値が26日、最大値が95日であり最大値が突出している。このような少数の大きな値が表れる分布における代表値は、値の小さいほうから、最頻値、中央値、平均値の順に並ぶという特徴がある。一方、データの分布が対称に近ければ平
均値と中央値はほぼ同じ値になる。
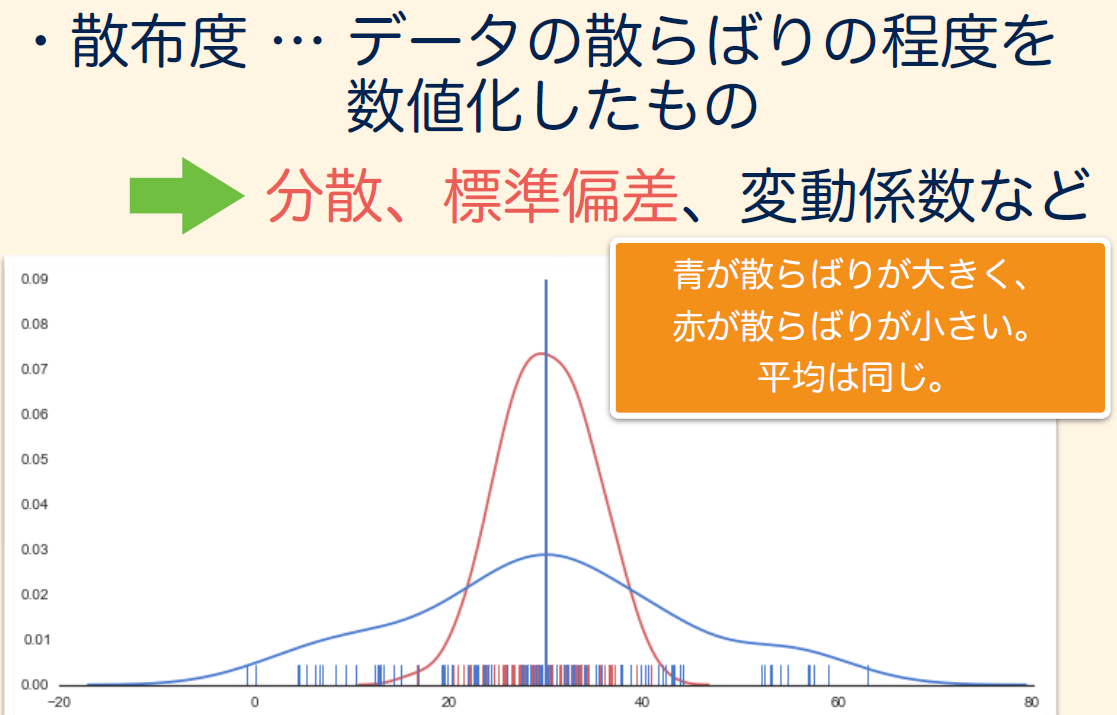
分布のひろがりを示す統計量:
ある変数の分布を要約する統計量。間隔尺度以上の変数における分散,標準偏差,範囲 range,変動係数のように分布の広がり(散らばり)を表す統計量の総称です。
範囲|レンジの求め方
データの中の最大値と最小値の差が範囲である、範囲は通常Rという記号で表される。
範囲R=最大値一最小値
範囲はデータの数が10のときにも、100のときにも、利用するデータは最大値と最小値の2
つだけなので、データの数が多いときには情報の損失が多くなってしまう。

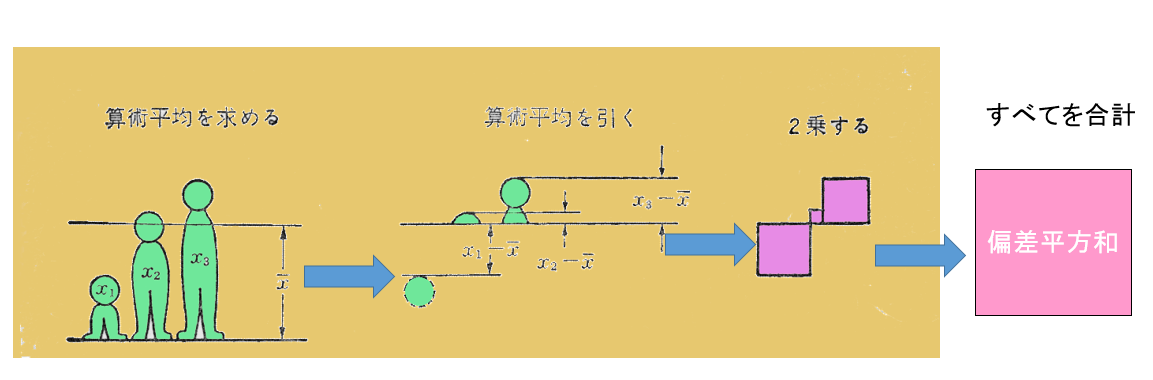
偏差平方和の求め方
X1個のデータX1,X2‥,Xnがあるときに,まず,これらのデータの平均値Xを計算する。つぎに,各データと平均値との差(偏差と呼ぶ)を求める。
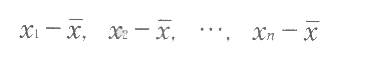
これら、1個の偏差の値は一つひとつ違っていて、同じ値にはならないので、偏差全体の大きさを考えることにする。このためには、偏差の合計値を求めればよさそうだが、偏差は平均値との差であるから、平均値よりも大きなデータのときには十、小さなデータのときにはーとなり、合計すると十一相殺しあって、常にOになってしまう。
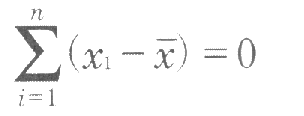
参考:∑の意味
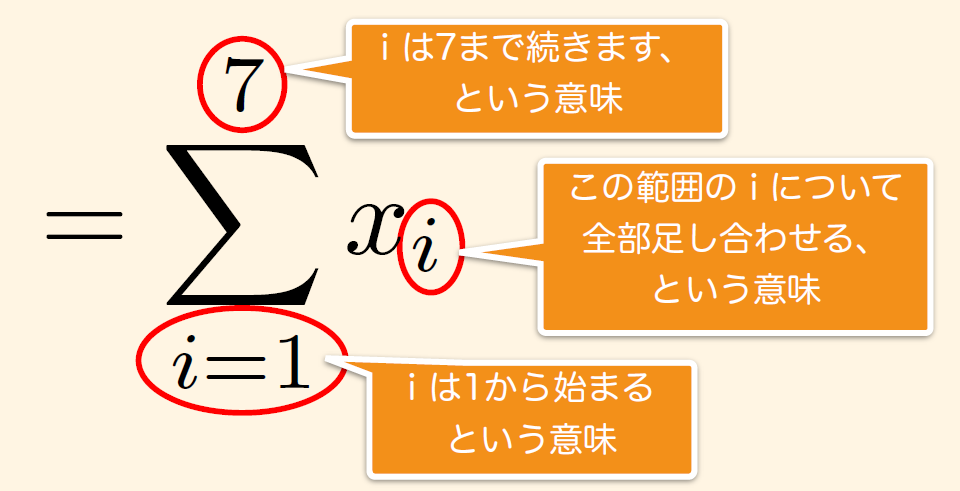
これではばらつきの尺度として使えないので、各偏差を2乗してから合計する。

こうして得られた値のことを偏差平方和という。偏差平方和はSで表す。
不偏分散|平均平方の求め方
偏差平方和は偏差の2乗の合計値であるから、データの数が多くなると、ばらつきの大きさに関係なく大きくなっていく。これでは、データの数が違うグループのばらつきを比較するのに不便である。そこで、偏差平方和をデータの数で割った値 Vを不偏分散もしくは平均平方と呼ぶ。
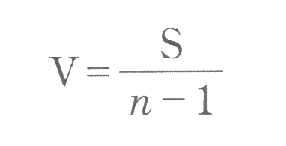

標準偏差の求め方
平均値の単位は、もとのデータの単位と同じである。しかし、偏差平方和や分散の単位は、もとのデータの単位を2乗したものになる。そこで、単位をもとのデータの単位にそろえるために、分散の平方根をとった指標Sを考える。これを標準偏差という。
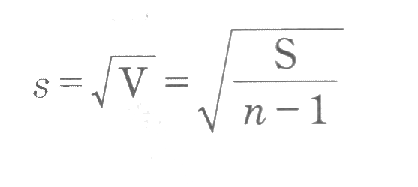
データの散らばり方を表す散布値
データがいろいろの値をとっていることをばらつきと呼ぶが、データのばらつきを示す数値が散布値である。散布値には、つぎの4つがある。
①範囲(Range) ②四分位範囲(quartile range) ③分散(Variance)
④標準偏差(Standard deviation)
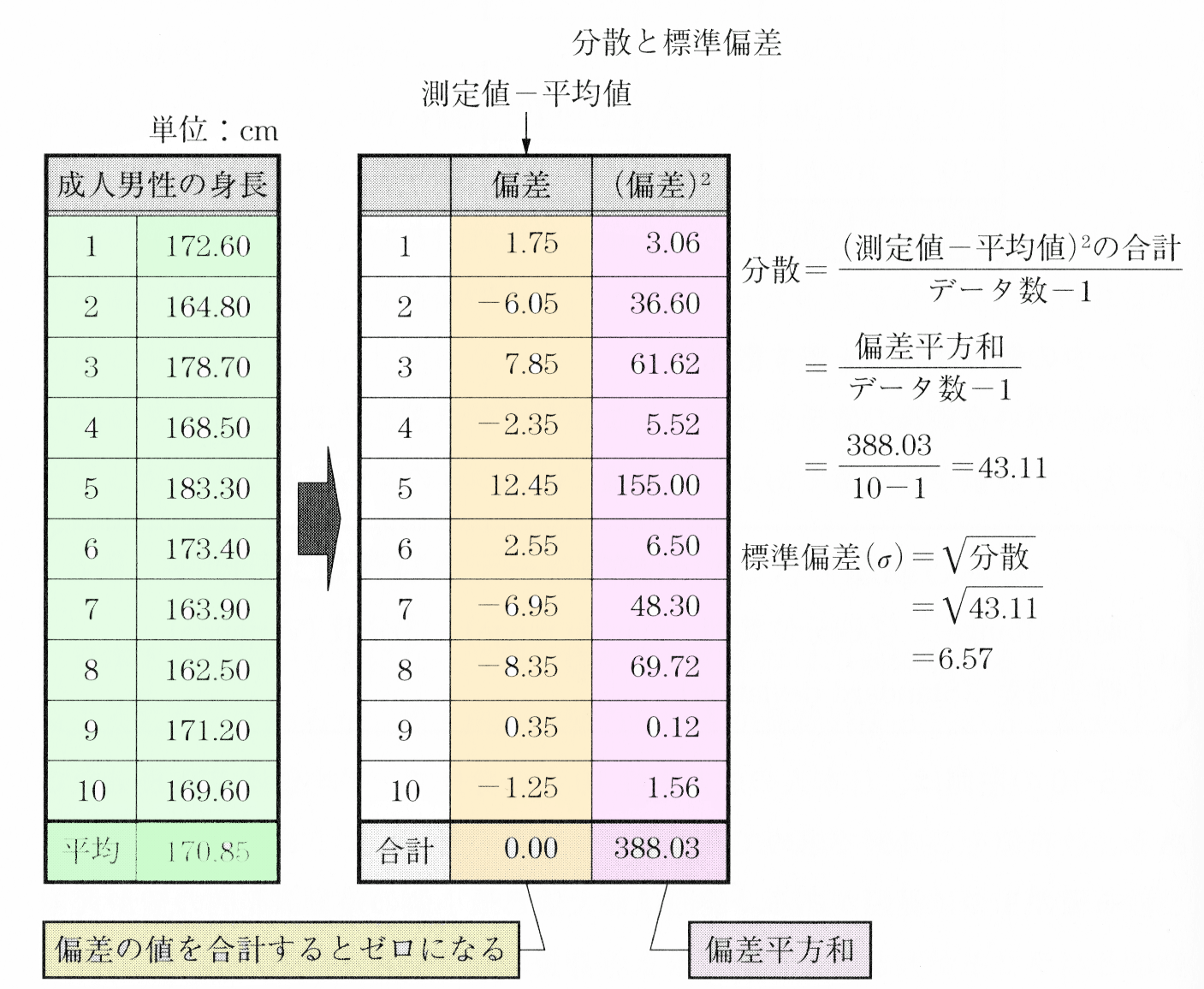
下表の左側は、日本人の成人男性10人の身長で、平均値は170.85cmである。散布値をこの例で求めてみよう。
散布値の1つに範囲がある。範囲は最大値と最小値の差で、範囲の値が大きいほどバラツキが大きいと判断できる。身長の最大値は183.30 cm、最小値は162.50 cm なので、範囲は183.30cmから162.50cmを引いて20.80 cm となる。範囲以外の散布値として、四分位範囲、分散、標準偏差などがある。

身長データーと範囲
分散と標準偏差((σ)の求め方
データのばらつきを知るために、各データ(測定値)と平均値との差を考えてみよう。[測定値一平均値]のことを平均値から偏って生じた差という意味で、偏差と呼んでいる。下表のように最初の人の身長は172.60cmなので平均値の170.85cmを引くと偏差は1.75cmとなる。
これら偏差をすべてについて計算し、その和を求めれば全体のばらつきがわかりそうであるが、偏差にはプラスの値やマイナスの値があり、合計するとゼ口になってしまう。そこで考えられた方法が、各偏差を2乗して全体のばらつきを求める方法である。最初の人の偏差は1.75 cm なので、偏差の2乗は3.06㎠となる。このようにして求めた偏差の2乗を合計すると388.03 ㎠となり、これを偏差平方和(全変動)とよぶ。
偏差平方和を(データ数-1)で割ったものを分散とよび、σ2(シグマ2乗)という記号で表す。身長の分散は、偏差平方和388.03 ㎠を9(10-1)で割って43.11 ㎠となる。
分散は2乗して加えたのだから、単位も含めてもとに戻すために正の値の平方根をとることにする。これが標準偏差((σ)であり、測定値が平均値のまわりに、どのように散らばっているかを示す数値である。
分散と標準偏差
平均と標準偏差
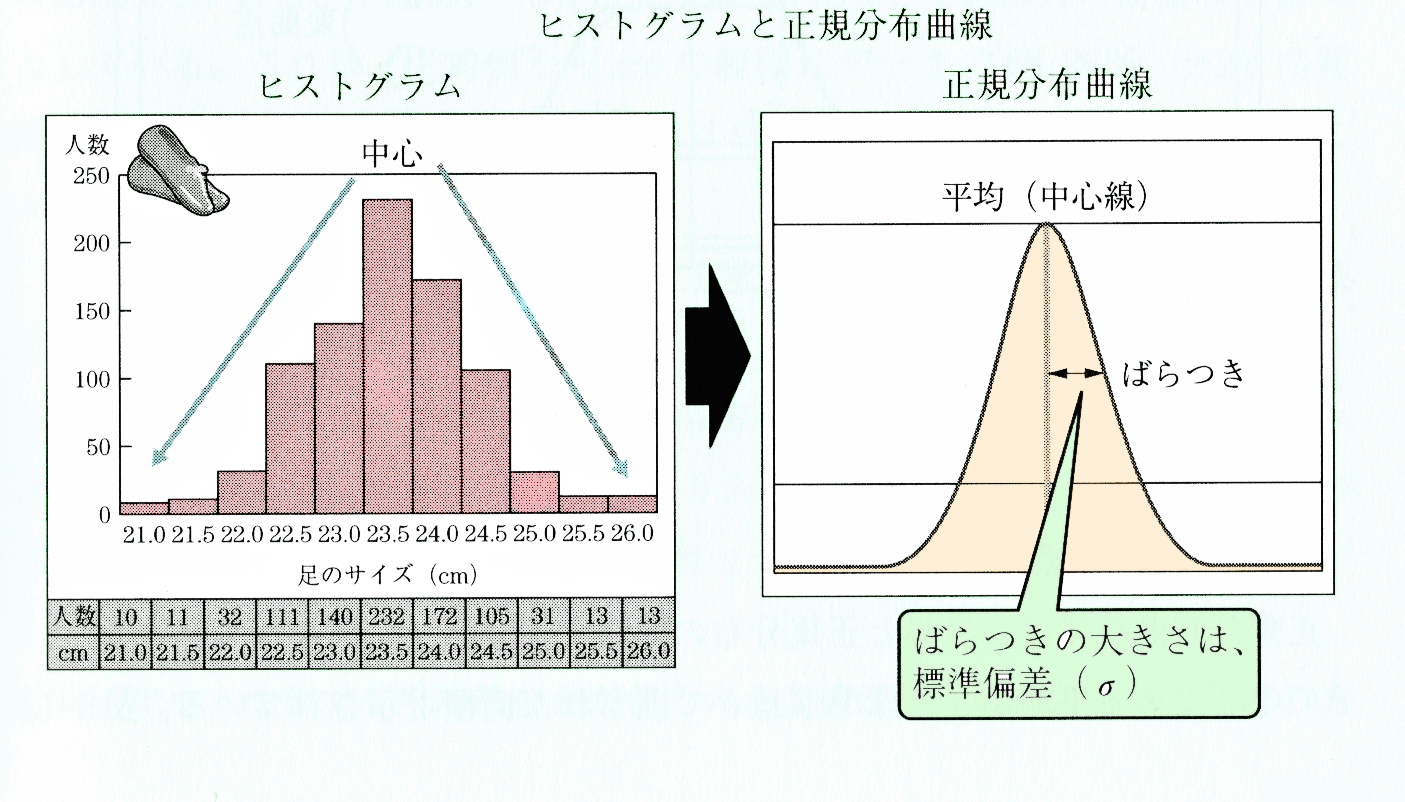
下表は、女性の足のサイズと人数のヒストグラムである。女性の足のサイズは23.5cmを中心に分布していることは、このヒストグラムより一目でわかる。足のサイズが大きくなったり小さくなったりするほど人数は少なくなっている。このヒストグラムを連続した曲線で描くと富士山のような形になる。
このような単峰で左右対称に裾の広い曲線を正規分布曲線とよぶ。
われわれのまわりには、正規分布曲線に従う例がたくさんある。たとえば、性別・年齢別にみた身長・胸囲・体重、工場で生産される製品の長さ・重さなどである。
正規分布 曲線
正規分布曲線の基本カーブ
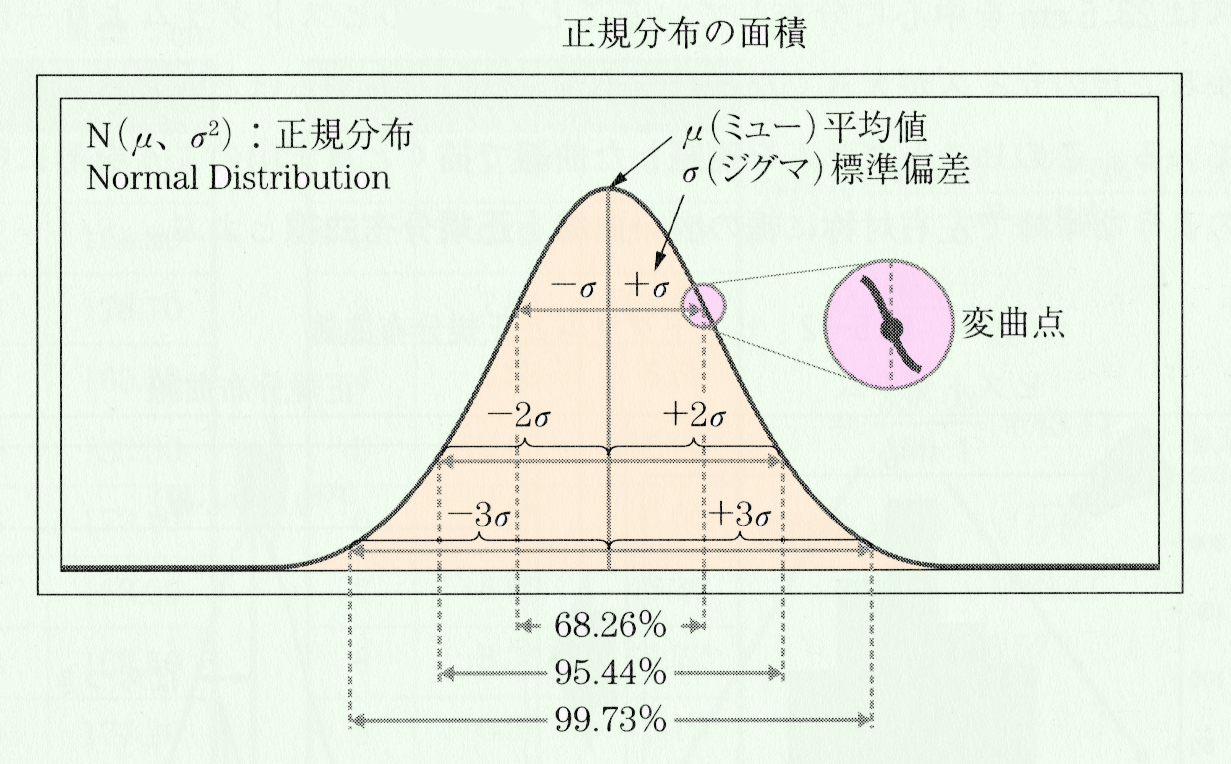
下図のように正規分布曲線は、平均値μ(ミュー)のところで最も高くなり、平均イ直を中心に左右対称な分布曲線であり、中心からの幅は標準偏差σ(シグマ)で数値化することができる。正規分布曲線は、平均値から右(十側)へ(σだけいったところと、平均値から左(-)へ(σいったところに変曲点がある。変曲点とは、右曲がりから左曲がりへ、あるいは左曲がりから右曲がりへ変わり、接線によって曲線が両側に分けられるような点である。
このように正規分布曲線は、平均値(中心線)と標準偏差の2つの要因で形が決定する。
正規分布の面積
正規分布曲線の面積
正規分布曲線では、横軸と正規分布の曲線で囲まれた全面積を1とすると、その中心である平均値μと標準偏差(Jで囲まれた面積が示されている。上表に示すように、平均値μ土σの面積は68.26%、平均値μ±σ(2×標準偏差)の面積は95.44%、平均値μ±3σの面積は99.73%、それ以外の面積は0.27%としている。
これは、平均値ら土σの範囲にデータの68.26%、±2σの範囲にデータの95.44%、±3σの範囲では99.73%のデータが含まれていることを意味している。
平均値と標準偏差を求めた日本人の成人男性10人の身長データ(下表)で確認してみよう。
身長データより平均値μ土σを計算すると、μ十σ=170.85+6.57=177.42、μ-σ=170.85-6.57=164.28になる。この範囲には、10人中6人の身長が含まれているので60%のデータが含まれている。さらに、平均値μ±2σの範囲にはすべてのデータが含まれている。
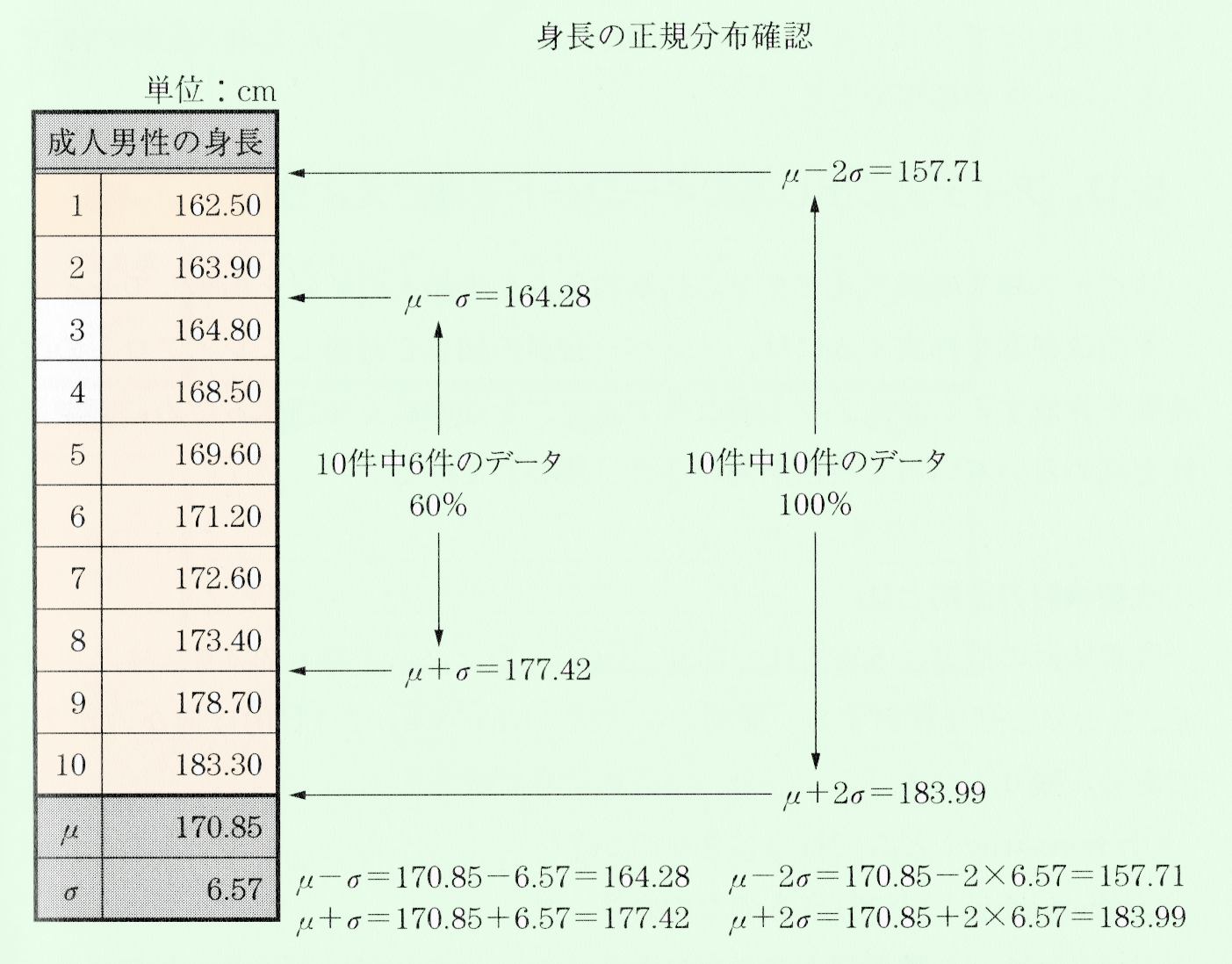
身長の正規分布確認
コメント