

















データリテラシーでウソを見破る!
統計データーを扱う能力(収集、分析、検証等)であるデータリテラシーは物事の本質を明らかにしたり、目的を達成するための解決策を効率的に知ることができます。
一方、その能力を悪用すれば社会、人を騙し、社会生活を混乱させて人を不安に陥らせます。
よって、統計データーに騙されない為にはデータリテラシーを学ぶのが最も効果的な対策法です。

データリテラシーとは?
データリテラシー(data literacy)とは、データ(data)の読み書き能力、活用する能力の事、広く言えば、データを扱う能力全般を言います。( literacy:読み書き能力)
広義のデータリテラシーはデータの集めかた、集めたデータの処理の仕方、データの表示や蓄積のしかた全般を含みます。つまり、データを作成し、提示する側の能力も含んだ意味となります。
狭義のデータリテラシーの意味は「データをどのように読んだらいいのか」「データにごまかされないためには」といった観点から作成を含まないデーター活用能力を育成する事です。
データリテラシーを悪用すれば情報を操作でき、人を騙すことができます、データーで騙されない為にはデータリテラシーを学ぶことが必須です。
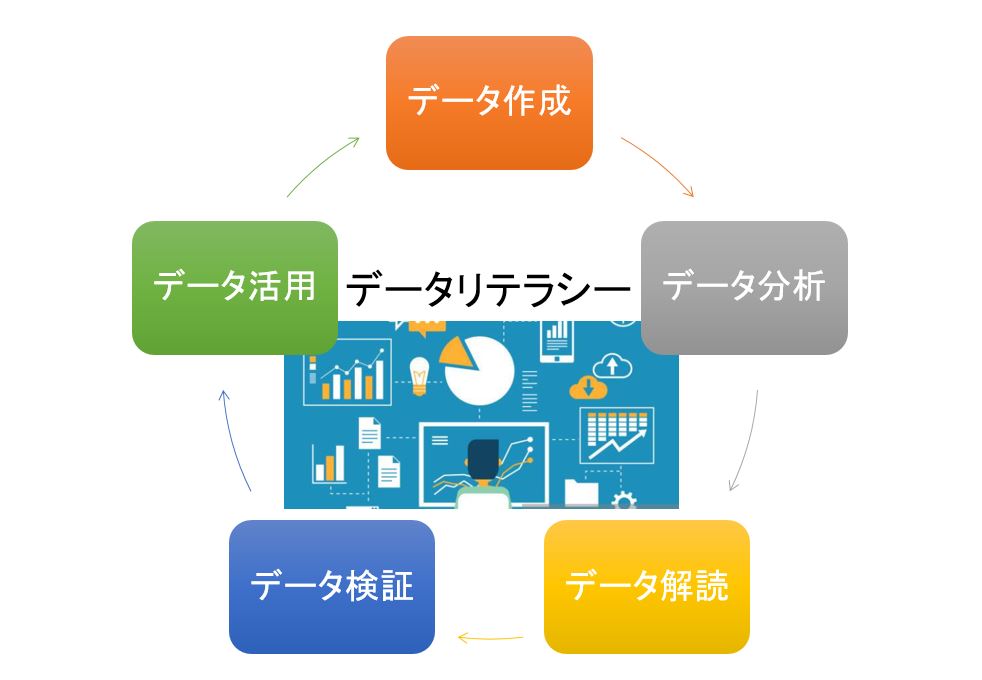
データサイエンスとは?
データサイエンスとは、数学や統計学、機械学習、プログラミングなどの理論を活用して、ビックデータの分析をし、将来の予測、商品の売り上げ予測等の有益な情報を導き出す学問のことを言います。
そして、データサイエンスを実行する者を「データサイエンティス」と呼んでおり、求められる能力は
①ビジネス力(ビックデータを活用しビジネスに活かす)
②ITスキル(ビックデータが保存されデーターベースを管理し、高速化する)
③統計解析スキル(ビックデータを統計処理し、視覚化する)です。

データリテラシーとデータサイエンスの違い
データリテラシー、データサイエンス どちらも定義が定まっていませんが簡単に説明するとデータサイエンスはデータを収集し処理するための手法、そのための数学的知識、コンピューターソフトウェアの使いかた、ビジネス活用などからなります。
それに対してデータリテラシーは統計処理する以前のデータに対する扱い方に重きを置きます、データについての常識に近いものです。
データリテラシーは、データサイエンスの一部を支えており、統計解析スキル(ビックデータを統計処理し、視覚化する)に該当します。
データーは嘘をつく
テレビのニュースや新聞、インターネットサイトなどで報道される数字のほとんどは、統計データーに基づいています。
データーサイエンスをうまく使えば、物事の本質を明らかにしたり、目的を達成するための解決策を知ることができます。
たとえば、コロナ禍では連日、国内外の感染者数やその推移が報道され、私たちを一喜一憂させています。 数字には強い説得力や影響力があります。
しかし、そうしたものが、すべて事実を表現しているとは限りません。
統計データや統計グラフには、実は「嘘」を内包しているものもあり、統計データやグラフを巧みに利用して、事実とは逆の情報を私達に与えて騙す場合が多くあります。
この講座では、統計や数字に騙されないためのポイントを身近な事例でわかりやすく解説しました。
![]()
客観的なデータなど存在しない
数字は嘘をつかない、数字にこそ真実が現れると言われてきますが本当でしょうか?
資本主義社会の全ての情報、統計データはプロパガンダ(宣伝)、情報操作などで恣意的に歪められています、客観的(自分の考えから離れて、ものごとを判断すること)なデータは存在しません。
数字の捏造、データの改ざん、事実の変造等 数字は嘘をつかないという言葉は現代ではもはや通用しなくなっています。

数字は嘘をつかないが嘘つきは数字を使う!
数字、データーしか信用しないという方が多くいます(特に男性)
しかし、この世界には絶対的なモノなど存在しません。
その数字自体が間違っている、データ自体が間違っているということまで考えなければ足元をすくわれる可能性があるということなので注意が必要です。
「数字は嘘をつかないが嘘つきは数字を使う」という伊藤惇夫氏の言葉があります。
数字は嘘をつかないが、嘘をつかせることができるというわけです。
嘘をつかせるのは『人』です、将来、AIが神のように万能の存在のモノになると考えている方がいますがAIを使うのも『人』です。

データリテラシーで人を騙す方法
彼を知り己を知れば百戦殆からず!(「孫子・謀攻編」の格言)
騙されない為に騙す方法を知る!ことが一番 有効です。
統計データー 比較の罠
2021年 学習塾 Aは東京大学へ300人が合格させ、一方 学習塾Bは60人合格、学習塾Cは30人合格させた。
貴方が学習塾が選ぶとしたしたらどの学習塾か?
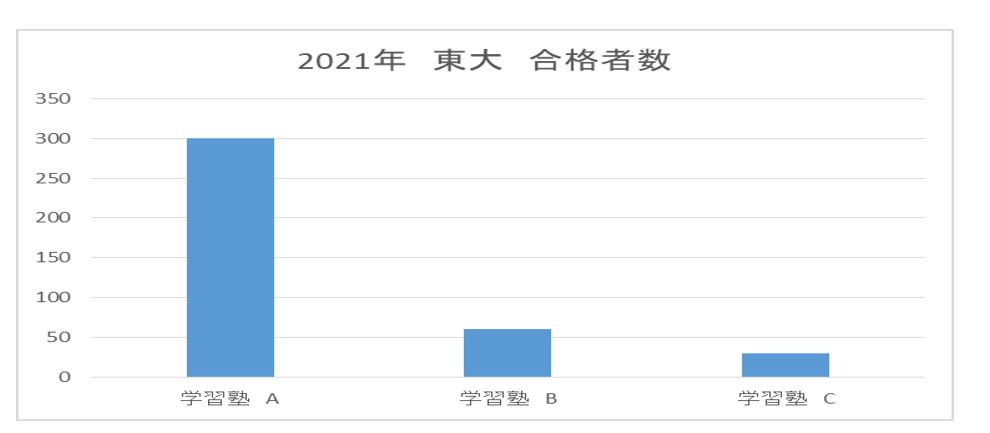
答えは発生した数字(合格者数)を比較しても無意味です、そのグループの分母で割り算して百分率(%)で比較しなけば優位性が評価できません。
又、ある時点だけでなく時系列で全ての推移データーを調査して比較、評価することも大切です。
百分率(%)&時系列でデーターを見える化したグラフが下記の図です。
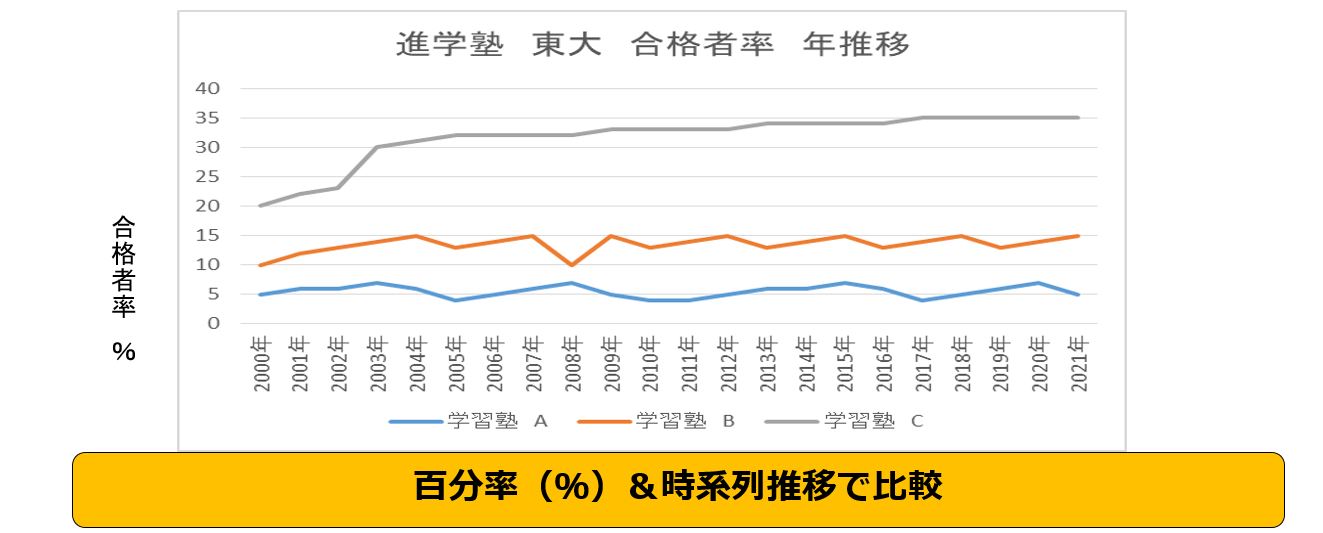
よって正解は学習塾Cです。
統計データー 比較の罠の事例
TV等で連日、新型コロナウイルス感染症の感染者数を都道府県別に比較した図が放映されているが感染者数だけでは統計データーとして信憑性に欠ける。
何故なら、都道県毎に人口が異なる、百分率 %で比較しなければ比較できない。

統計データー 平均値の罠
有名な製薬会社から平均寿命が3年延びる画期的なサプリメントが発売され、TV、新聞で大々的に宣伝されている。
貴方はこのサプリメントを購入するか?
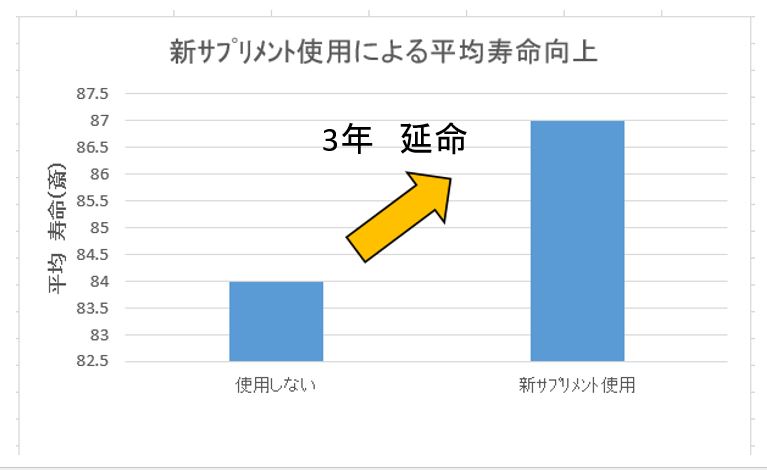
- 平均値は情報を素早く伝え事ができ、現代社会では多くの統計データは平均値で表現されている。
- しかし、情報を単純化すると真の姿が見えなくなる、平均値を使うと分布(バラツキ、MIN、MAX)が見えなくなる。
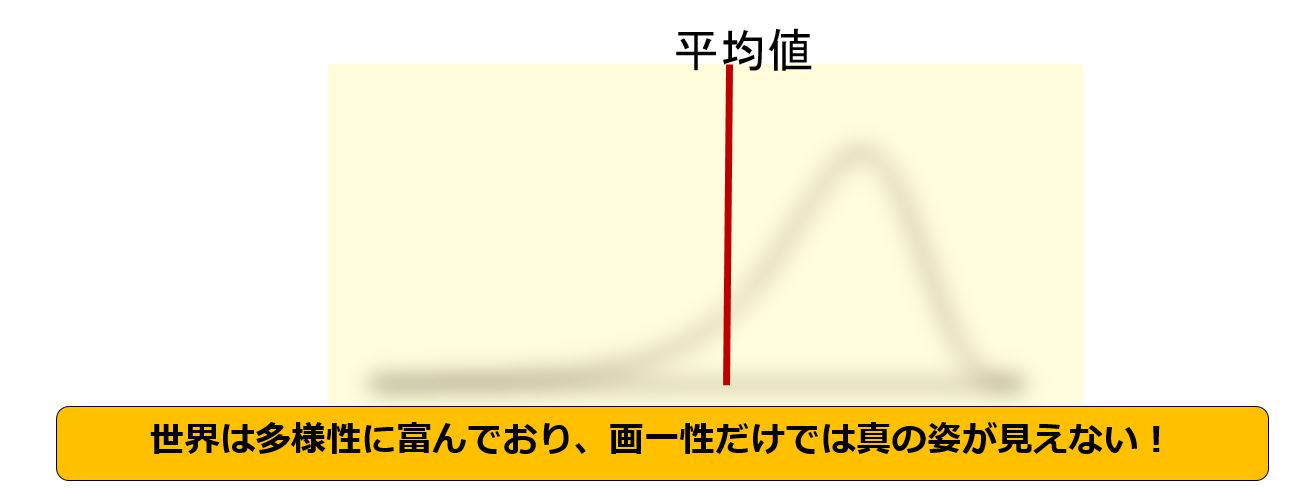
新しいサプリメントを使用した寿命の正規分布は下記の図であり、効果ある人もいれば逆に寿命が短くなる人もおり、平均値だけでは効果を比較できない。

又、現在だけでなく過去のデーターと比較することも大切である。
平均寿命の場合は日本だけでなく、どの国でも平均寿命が延びてきており、薬、サプリメントを用いなくても年々、平均寿命が延びてきている。

会社、家庭及びTV、新聞、ネットで使用している統計データーはほとんどが平均値は表現されている。
確かに情報がひとつの数字で表現されており、便利であるが情報を単純化すると真の姿が見えなくなる、平均値を使うと分布(バラツキ、MIN、MAX)が見えなくなる。
宇宙、世界は多様性(ダイバーシティー:diversity)に富んでおり、画一性、均一性(ユニフォーマル:uniformity)のデーターだけでは表現できない!!
統計データー 平均値の罠の事例
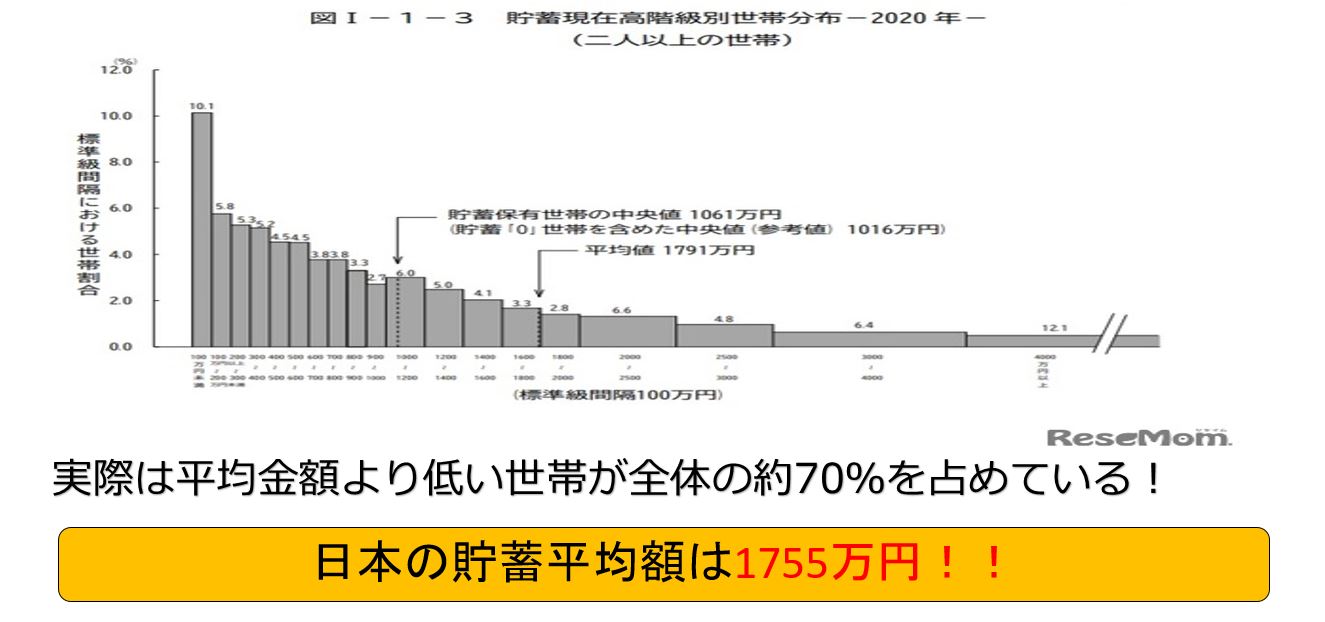
日本の貯蓄平均額は1755万円と驚くデーター、しかし実際には平均貯蓄金額より低い世帯が全体の約70%を占有している。
逆に言えば約30%の人が1755万円以上の貯蓄しているが大半の約70%は1755万円以下となり、納得のいく数字となる。
統計データー サンプリングの罠
サンプリング(標本抽出)の思考は人類の歴史はじまって以来のものです、人類に限らず他の動物も,食物の一部をサンプリングして味見します。
古来より恣意的なサンプリングで様様なウソに使われ、データー捏造に用いられてきました。
例えば
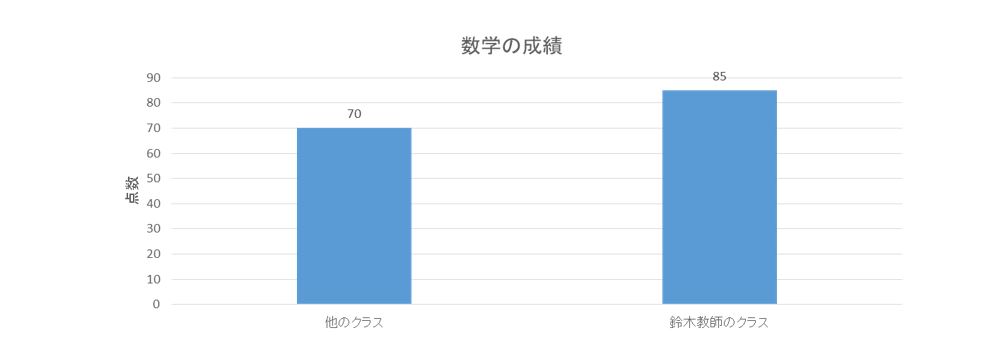
数学担当の鈴木教師が自分の担当するクラスの1年間の成績をサンプリングして生徒の成績を拾い出して平均値を算出したら他のクラスの数学成績より点数が良かった。
よって鈴木教師の教え方は優秀であると評価された。
”ほんとう?”
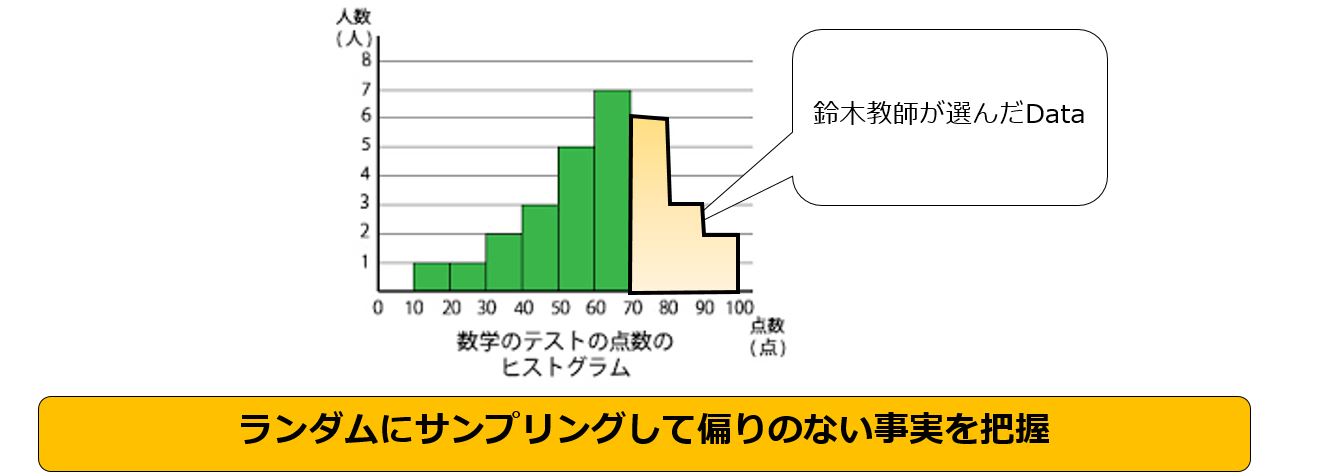
サンプリングで重要なことは『偏り』に気を付けることです、つまり サンプルとして抽出さたグループが特殊なモノになっていないかということです。
せっかく、事実をベースに論理を組み上げてもその対象となるDataに偏りがあるとその論理の信憑性が崩れます。
具体的には自分の望む方向に片寄せてサンプルを抽出したDataでは信憑性が疑われます。
上記の『数学の成績』の鈴木教師の評価ですが鈴木教師が選んだ生徒のサンプルは故意、無意識は不明ですが下の図のように成績が良い生徒のデーターを抽出しました。
よって、結果は当然ですが成績が良くなります。
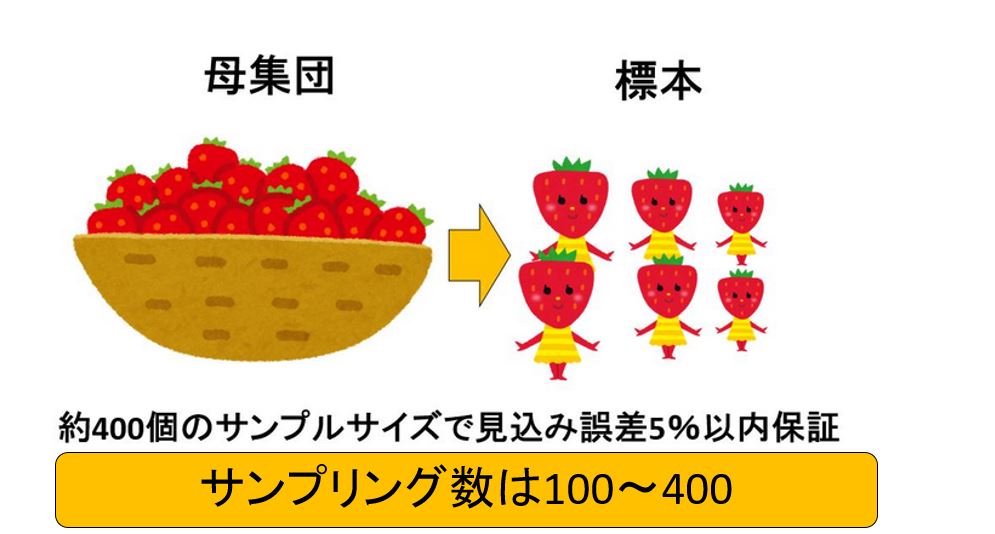
サンプリング数はいくつか?
統計学上 サンプリング数は100~400が良いとされており、サンプル数が多いほど、算出値の信頼度が高くなります。
ランダム・サンプリング採用
サンプリングで『偏り』が発生しないように母集団から標本を無作為に抽出する方法の1つにランダム・サンプリングがあり、その際に乱数サイコロ、乱数表等のツールを用います。
これを使用することにより不自然な『偏り』のないデーターを抽出できます。
しかし、手間と時間がかかりますので誰もやりたがりません。

統計データー サンプリングの罠の事例
TVのCM等で放映している専門家 お勧めの商品です。
”売上げ No1 90%の歯医者が使用しているブラシ”

統計データー グラフの罠
統計データーをグラフ化にすると目で分かるようになるがそこにも罠が仕掛けられている。
テレビを始めとするマスメディアがよく使う統計データーを誇張する為のグラフに気を付ける。
下記はインフルエンザの感染率を時系列で棒グラフで表したもので1月4日から急増しているように見える。
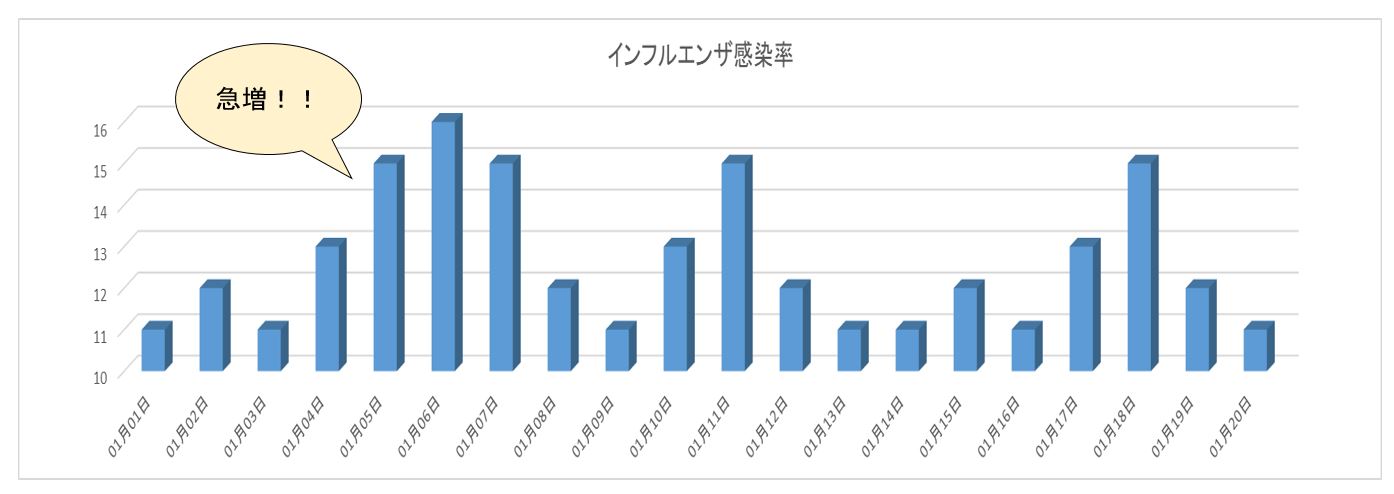
しかし、グラフのY軸を0(ゼロ)から始めるグラフに変更すると下記の図のようになりインフルエンザ感染率はバラツキ範囲内で急増はしていない。
自分自身の主張をより効果的に伝える為に、グラフの軸の大きさを調整する事は、昔から頻繁に使われる手法であり、原則としてグラフのY軸は常に0(ゼロ)から始まるべき。

統計データー グラフの罠の事例1
3D円グラフは、その傾き具合によって、手前と奥側、そして横側に置かれている領域の見え方が異なって見えてしまいます。
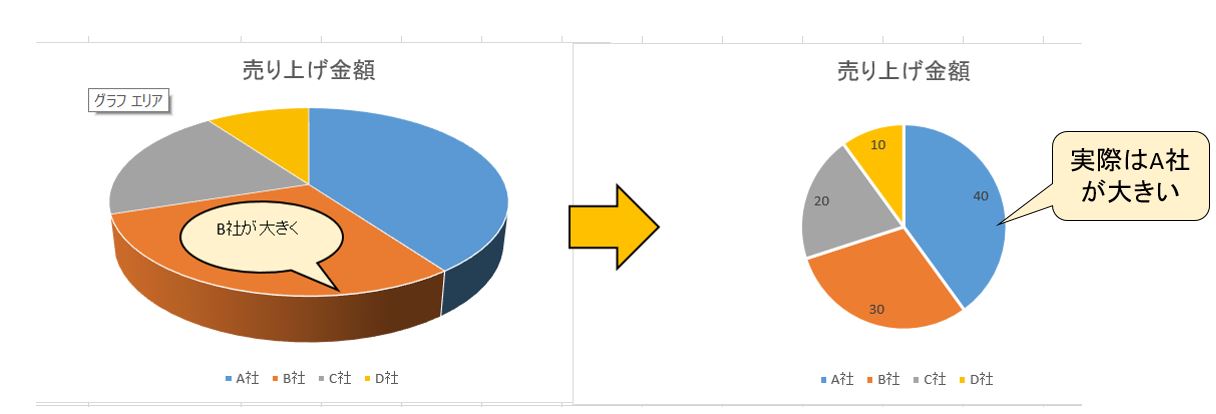
統計データー グラフの罠の事例2
自分の都合の良い期間だけを誇張してグラフ化する。
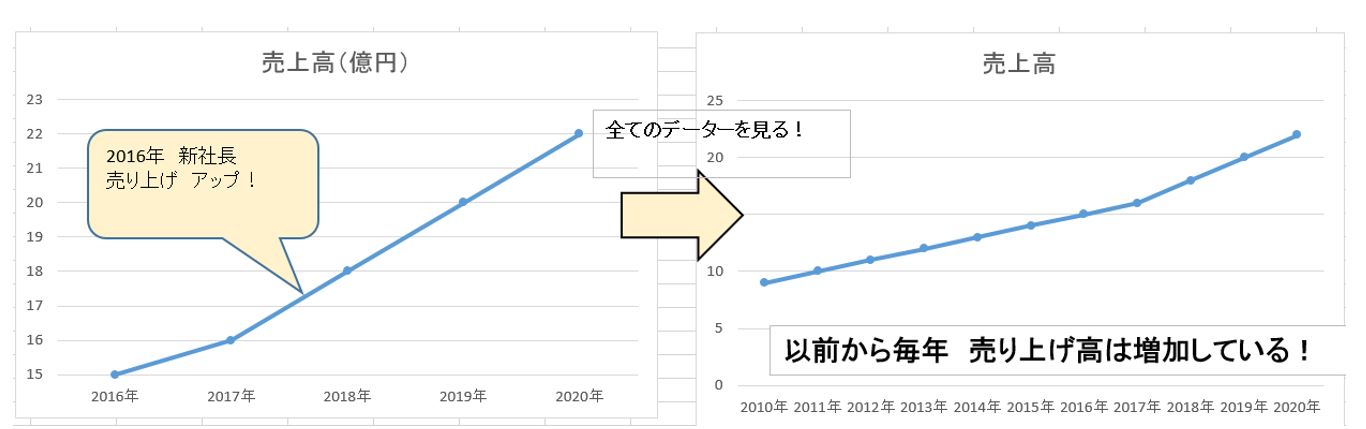
統計データ 定義の罠
統計データーの定義(調査方法、測定方法、サンプリング方法等)が異なってるデータの比較では真実が見えない。
最近、TV広告で有名なAAA専門学校は卒業生の就職率が100%である、全ての卒業生が様々な企業に就職していた。
”ほんとうか?”

AAA専門学校は『就職が決まらない生徒は卒業させないで就職が決まるまで無料で支援する』制度があるので、その結果 卒業生は全員が就職が可能となる。
成功者だけを基準に判断する事を『成功者バイヤス(Bias:偏り)』と呼ぶ、当然であるが成功者だけをサンプリングすれば必ず100% 成功する。
例え話であるが昔、雨乞いに優れた祈祷師がいた。
彼女が雨乞いの踊りを踊ると必ず、雨が降りだした。
何故ならば雨が降るまで踊っていたので100% 雨が降った。

統計データの定義で騙されない為にはデーターの出処、日時、測定方法、測定者を確認し、定義が同一である事を見極める必要がある。
つまり、科学の分析と同様に極力同一の条件でデーターを取り、比較しなければ真実は見えてこない。
統計データ 効果の罠
使用後の効果をデーターで表示し、劇的に改善効果がある薬、商品をTVでは放映しているが効果を科学的に検証するには『仮説検証』をし、本当に効果があるかを検証しなければならない。
“あるウィルス感染症の治療薬として開発された新薬『スグナオル』を患者に飲ませたところ、89%の患者に改善した兆候が見られた。この薬は有効であるか?”

人が病気に罹り、薬で治療を行う際に偽薬を飲ませても症状が改善する場合がある、これをプラセボ効果という、これは生物、人間には免疫力があり、病気、怪我をしても自然と治る力がある為である。
よって、新薬『スグナオル』が効果があるとは断言できない。
子供の身長が伸びる、頭が良くなる薬、トレーニング等のCMも同様である。
元々ある能力(免疫力、成長率等)を考慮した実験を手間と時間をかけて検証しないと効果の有無は簡単に分からない。

- 効果を検証する為に『仮説検定』という方法を用います、『仮説検定』とは確認したこと反対の仮説を立てて、それが否定されるかどうかを調べる。
- 新薬の場合は新薬と偽薬の効果に差がないと仮定(帰無仮説)し、この仮説が棄却されれば差があると判断され、新薬に明らかに効果があることが検証される。

統計データ 教育、躾の罠
親はその当時の常識、考え方を子供に教育します。
そして子供は小学校で当時の統計データーで社会教育を受けます。
しかし、世界、社会は変化します、その変化に合わせて自らが再学習しないと社会人になった時、20年前の思考パターンで自分だけの思い込みで生活する事となり、現代社会と矛盾が発生することになります。
外部世界は常に変化します、それに順応して内部の世界(思考)を変化させなれれば必ず、ミスマッチが生じます。
統計データーも不変ではありません、情報を得た瞬間から変化します。

例えば”現在の世界の平均寿命は?”と聞かれた場合、多くの方が50歳、60歳と答える。
しかし、正解は70歳である。
誰もが再学習しない限り、過去の教育を受けていた時代の思考パターンで現在を生活している事となり、外部世界とのズレが発生する。
比喩的な例を上げると車を運転する時に人は最新の道路の状況に合わせたスピードで車を運転します、過去の1分前の道路の状況で運転しては必ず、事故を起こします、車を運転す時は思い込みでなく、最新のデーターを収集して判断して運転します。
如何に世界が変わっても思い込みでなく、最新のデーターを収集して思考、行動する事が必要です。
統計データ 教育、躾の罠 事例
50年前は西洋諸国(ヨーロッパ、アメリカ)が世界の経済を握っていたが世界中の所得が現在のペース進むと今から20年後の未来、2040年にはそれが逆転し、西洋諸国以外の国が世界経済の覇権を握るようになる。
世界は徐々にであるが変化しており、その変化を読み取ることが外交、ビジネスで重要になる。

プロパガンダ(宣伝)の罠
プロパガンダとは、特定の思想・世論・意識・行動へ誘導する意図を持った行為の事。
第二次世界大戦時のナチのプロパガンダが有名。
TV広告、ネット広告でも人の心理を利用した商品の購買を目的としたこの手法が使用されている。
プロパガンダ手法とは
・一部のみを切り取り、そこを大々的に報道する
・恐怖、安心を与える印象操作
・レッテル貼り
・繰り返し報道
・権威の活用
・嘘を堂々と流す
・論点を誘導する

プロパガンダ 手法に騙されない為には論理力を養うことが必要、特にクリティカル・シンキング力(批判的思考力) が必要。
批判的思考とは、人の意見を傾聴し、なぜなぜを繰り返して、真の原因を追究し、共同してよい社会を築いていくうえでも大切な思考です。
現代は、何か分からないことに直面した場合、スマホのインターネット検索などで簡単に答えを見つけられる便利で効率的な社会になってきており、自分で考えない大人、子供が増えているが昔も将来も自分で「考える力」が必須。
何故ならばネットで情報が溢れいる現代社会で客観的な情報など存在せず、何らかの恣意的な意図が含んでいる情報が大半だからです。
論理力を養う時に下記の番組が参考になります。
統計データ 本能の罠
人間は正しいデーターに基づく事実でなく動物的本能で『世界をドラマチックに見る見方』で世界を見て、行動している。
その本能とは
①分断本能(世界は分断されている思い込み)
②ネガティブ本能(世界はどんどん 悪くなっている思い込み)
③直線本能 (『上昇がひたすら続くと』いう思い込み
④恐怖本能 (危険でないことを恐ろしいと思う、思い込み)
⑤過大視本能 (『目の前のDataが一番重要』という思い込み
⑥パターン化本能 (『ひとつの成功事例がすべてに当てはまる』という思い込み)
⑦宿命本能 (すべては運命だと思う、思い込み)
⑧単純化本能 (世界はシンプルだと思う、思い込み)
⑨犯人捜し本能 (人を攻めれば問題が解決すると思う、思い込み)
⑩パニック本能 (いますぐ、行動しないと大変になると思う、思い込み)
引用先:
FACTFULNESS(ファクトフルネス)10の思い込みを乗り越え、データを基に世界を正しく見る習慣より

我々の祖先であるホモ・サピエンスは地球に20万年前に出現し、長年 飢えと闘いながら狩猟生活を続け生き延びてきた。
その間に生きる為に身に付いた本能が現在でも我々を支配している。
当時の生活は情報も少なく、現在のように時間をかけて分析、検討する余裕はなく、生きる為にはすぐに行動を起こさなければ『死』に繋がるケースが多く、本能で行動する方が生きる確率が高かったのではないかと推測される。
例として、虎と遭遇した時にはジーと判断しているよりは”パニック本能”が機能して”一目散に逃げる”という行動のほうが生存確率が高かったのではないか?

世界をドラマチックに見る本能、劇場型に見る本能の事例は下記のとおり。

分断本能
人は誰しもさまざまな物事や人々を2つのグループに分けたがる、例を挙げれば世界の国々や人々が「金持ちグループ」と「貧乏グループ」に分断されているという思い込み。
しかし、多くの場合、「完璧に分断された世界」は存在せず、思い込みによって「間違った認識を持ってしまい、真実や事実を分からなくなります。


参考資料:
FACTFULNESS(ファクトフルネス)10の思い込みを乗り越え、データを基に世界を正しく見る習慣
FACTFULNESS(ファクトフルネス)の詳細は下記の記事を参考にしてください。
関連記事:ファクトフルネス データーの正しい見方【イラスト図解】
データリテラシーでウソを見破る!
情報を明確に伝達するツールとして5W+1Hという手法があり、下記の要素を意識して文章作成、伝達すれば物事を明確に具体的に伝えられるようになります。
①なぜ?(Why)
②誰?(Who)
③どこで?(Where)
④いつ?(When)
⑤何を(What)
⑥どのように?(How)
この 5W+1H利用して統計データのウソを見破ります。
特に初心者で統計分析が未熟な方でも5W+1Hをキーワードに分析を行うとミスを起こさず、データーのウソを見破ることが可能です。
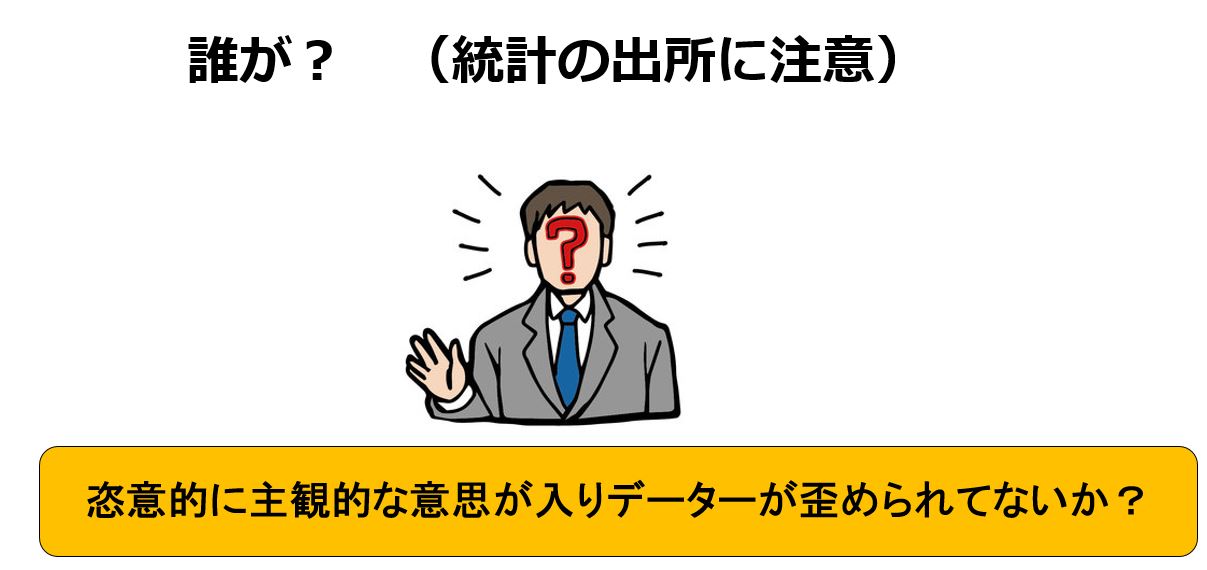
誰が? Who?(統計の出所に注意)
まず最初に誰が? データーを作成したかです。
気をつけるべきことは 作成者の偏り(バイアス)である。
例えば、何かを研究している研究所で目的が純粋に理論を完成するためにしているのか?
評判をよくするためにしているのか?それとも依頼者(メーカ)からの要求なのか?
また、別の例では賃金を問題にしているのは、労働者側か経営者側か、といったようなことに気をつけてみるのである。
又、ある情報に威厳を与える為に研究成果のレポートに有名な専門家の名前を入れる事です。有名な医療の医者や専門家、研究機関、大学、大企業等の名前を見れば、多くの人は自動的に彼らが作成したレポートの結果を信用するようになります。
ただほとんどの場合、この様な専門家がそこにある研究をしたのでは無くて、実際には意味が無い程度にしか関わっていなくて、人々をただ説得する為だけに名前が付け加えられているだけに過ぎない事が多いのです、一言で言えば、[何を言うかより、誰が言うか]に焦点を当てた情報操作手法です。
又、誰を(Whom)対象としたデーターなのかも注意する必要があり、サンプリングの対象者の定義が曖昧だと意図したデータとは異なったデーターとなります。
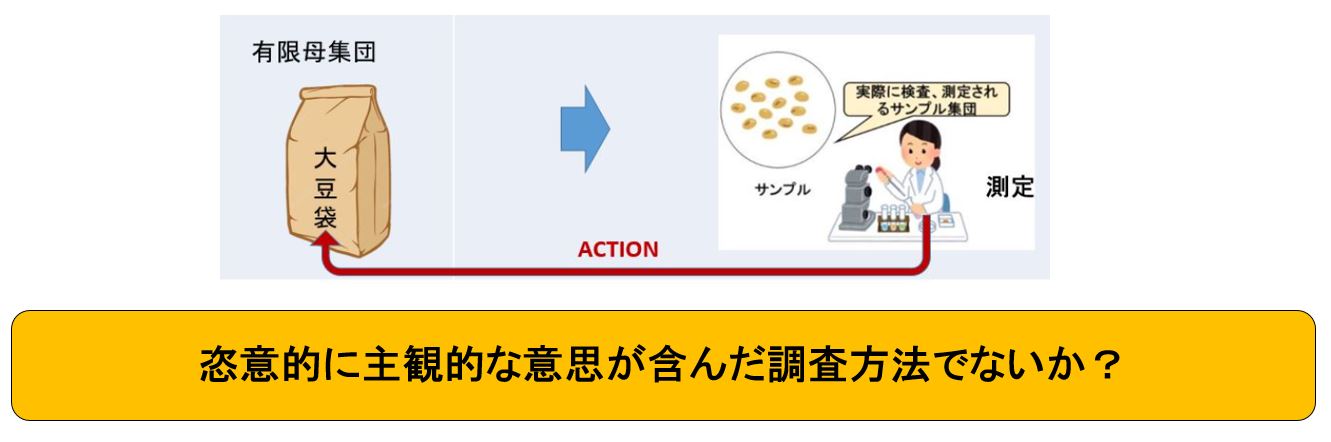
どのように?How?(測定、調査方法、サンプリング)
偏りのあるサンプルに注意しなければいけない。つまり、サンプルの選び方が不適当でない、あるいは、調査の結果でてきたわずかなものだけを選んだのではないかに気をつけることである。
調査方法についても誘導尋問で恣意的に結果に影響が与える調査法でないかを確認する必要がある、又、統計的に信頼できるサンプル数であるか、注意しなければならない。
具体的には下記のようなHow?があります。
①対象の選び方:どのように調査対象を選んだのか?
②調査方法の選び方:どのような調査方法を使ったのか?
③質問の方法:どのように質問、アンケートをしたか?
④どのくらい:調査対象者は何人?
いつ?When?(測定、調査時期)
統計データを分析する際は時間は重要なファクターである。
いつ、測定、調査したのか? データーが古くはないか? 測定時期が不明でないか?
を疑って確認する事が必要である。
又、統計データーを比較する際にも都合の良い時間軸だけを切り取り、比較してないか?
全ての時系列データーが対象になっているか、確認する。

どこで?Where ?(測定、調査場所)
統計データを分析する際は場所は重要なファクターである。
どこで測定、調査したのか? 日本か? 海外か? 月か? 宇宙か?
を疑って確認する事が必要である。
又、統計データーを比較する際にも同じ場所でなければ正しい分析はできない。
例としてダイエット後に効果を確認する為に月に行き、測定したら正しい分析、評価はできない。

何故?Why?(測定、調査目的)
統計データを分析する目的が何かの商品を販売する為、会社のプロジェクト成果を報告する為の場合、統計データーに恣意的に主観が入り、統計データーが歪められる。
統計データーの作成目的、意図が何かを見極めてから注意して統計データを見ることが必要である。
例としてダイエット商品の広告は自社の商品が如何に優れているかを巧みに統計データを利用して消費者の心理を突いて商品を購入させようとする。

なにを?What?(測定、調査対象)
何を測定、調査対象にしているのかが曖昧、不明だと層別比較が不可能になる。
逆に測定、調査対象を曖昧にして恣意的に自分の意図する統計データを測定、調査する事ができるので何を測定、調査対象にしているのかを明確に定義しておく必要がある。
よって測定、調査対象の定義が明確化を確認する必要がある。

まとめ
ネット活用により高度に情報は発達した現代社会ではデーターサイエンスでビックデーターを活用することがビジネス、生活において非常に重要です。
しかし、如何に優れたプログラムを作成しデーターベースを構築しても基となるデーターが『嘘』では元も子もない、且つ、データリテラシーを悪用すれば社会を恐怖と混乱に陥らせる。
データー、数値は大切であるがそれと同様に現実、現場、現物を見ることが大切である、実際に現場に行き、現物を見て、現実を知ればデーター、数字が正しいのかが体で体験できる。
例えば気象庁の天気予報の風速、気温をだけを見て今日は富士山の登山は問題ないと判断して登山をすると予想に反して暴風、ホワイトアウトで遭難するケースがある。
又、将来 いくらAI(計算機)が発達してもINPUTするデータ情報が不正確又は恣意的に歪められいては正しく世界がみえず、人間社会に貢献することはできない。
現場に行き、現物を見て、現実を知りその上でデーター情報を分析すればより正しく世界を見ることができ、実際の現実にマッチした改善、アイデアが創出できる。

スライドシェア 無料ダウンロード 資料
スライドシェアから無料で資料がダウンロードできます。
参考文献:
統計でウソをつく法 著者:ダレル・ハフ
FACTをつかむ 統計の見抜き方 著者:現代ビジネス
コメント