
















この記事では、ChatGPTを使った分散分析の学び方・手順・事例・注意点・今後の展望を、初心者の方にも分かりやすく解説します。
AI ChatGPTで分散分析を学ぶメリット
ChatGPTとAIによるデータ分析の基本
ChatGPTは、文章生成だけでなくデータ分析支援ツールとしても活躍します。
従来の統計分析は、「統計ソフトの操作」や「数式理解」が必須でしたが、ChatGPTなら自然な会話形式で質問しながら進められます。
💬 例:
「3つのグループの平均値に差があるかを確認する分散分析をしたい」
と入力するだけで、ChatGPTは分析手順や必要なデータ構造を提示してくれます。
このように、ChatGPTを使えば「統計の理論」と「実務での使い方」を同時に学ぶことができ、初心者でもスムーズにデータ分析に取り組めます。
分散分析とは?基本概念の解説
分散分析(ANOVA:Analysis of Variance)とは、複数のグループ間で平均値に差があるかどうかを調べる統計手法です。
たとえば、次のようなケースで使われます。
-
-
3つの広告パターンで購入率に差があるか
-
4種類の肥料で植物の成長に違いがあるか
-
3つの店舗で売上に有意差があるか
-
植物成長 肥料の種類 違い
社内での利用事例と活用方法
ChatGPTを社内業務に取り入れると、分散分析の導入ハードルが一気に下がります。
以下のような分野で活用されています。
| 部門 | 活用シーン | 効果 |
|---|---|---|
| マーケティング | 広告パターンの比較 | 効果的な施策選定 |
| 製造 | 工程ごとの品質差分析 | 不良率の改善 |
| 人事 | 研修コース別成果比較 | 教育効果の可視化 |
💬 ChatGPTを社内の分析サポーターとして使うことで、専門部署に依存せず、現場レベルでデータドリブンな意思決定が可能になります。
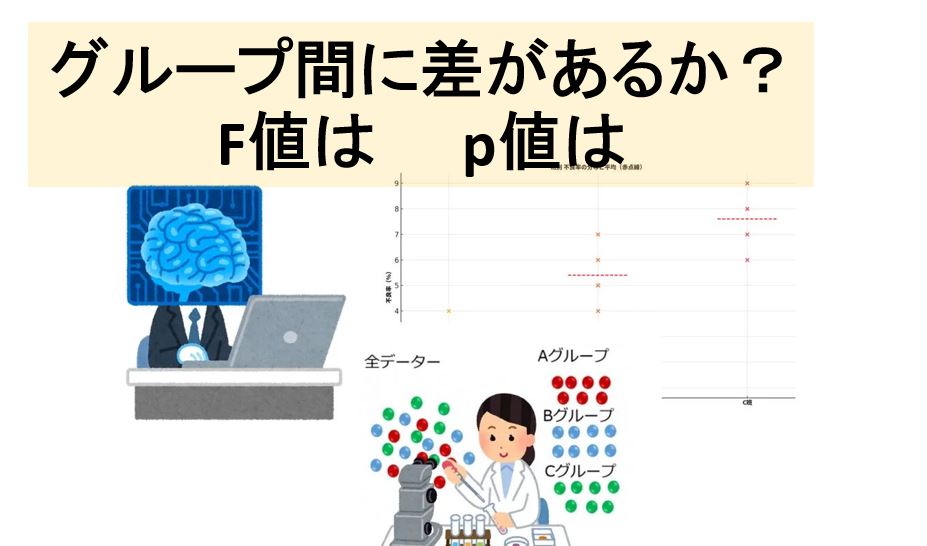
層別分析と分散分析の違いとは
層別分析(そうべつぶんせき)と分散分析(ぶんさんぶんせき)は、どちらも「データの違い(ばらつき)」を理解するための分析手法ですが、目的・使い方・得られる結論がまったく異なります。
以下に、わかりやすく比較して説明します👇
目的の違い
| 項目 | 層別分析 | 分散分析 |
|---|---|---|
| 目的 | ばらつきの原因を「グループ(層)」ごとに分けて原因を探る | グループ間の平均値の差が統計的に有意かを検定する |
| 例 | 不良率が「作業者A・B・C」で違うかを確認したい | 作業者間で平均不良率に有意差があるかを検証したい |
🔹層別分析は、「違いを見える化する」ことが目的。
🔹分散分析は、「その違いが偶然ではないといえるか(統計的に有意か)」を判断する。
分析方法の違い
🔹層別分析では「層ごとの特徴」を肉眼で確認するのに対し、
🔹分散分析では「差がある」と数値で裏付ける。
使う場面の違い
| フェーズ | 層別分析 | 分散分析 |
|---|---|---|
| 現状把握 | ✅有効(どの層に問題があるかを確認) | ❌まだ早い(原因特定前) |
| 仮説検証 | ⚪一部利用 | ✅有効(差が統計的に有意か確認) |
例:
-
まず層別分析で「Aラインだけ不良が多い」と見える化。
-
その後、分散分析で「Aラインと他のラインの差が有意か?」を確認。
👉 両者はセットで使うと最強!
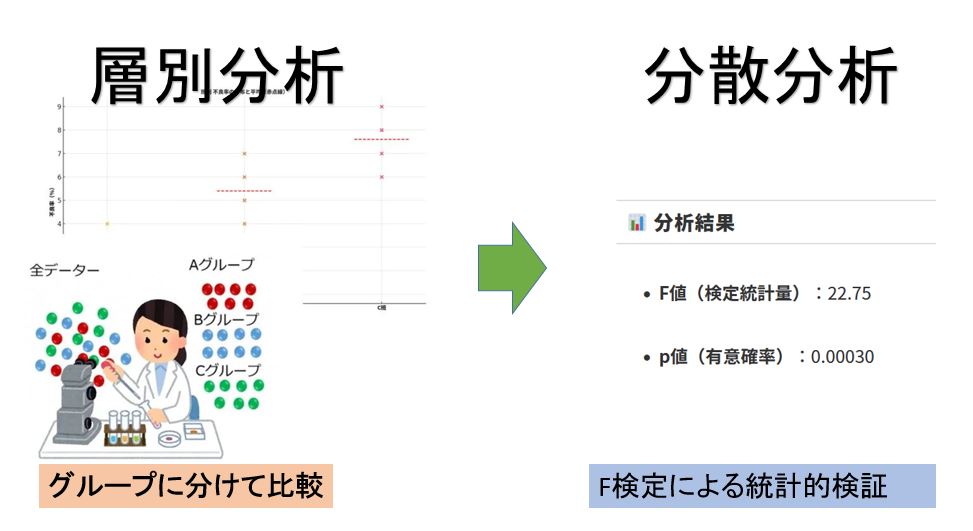
層別分析と分散分析の違い
具体例
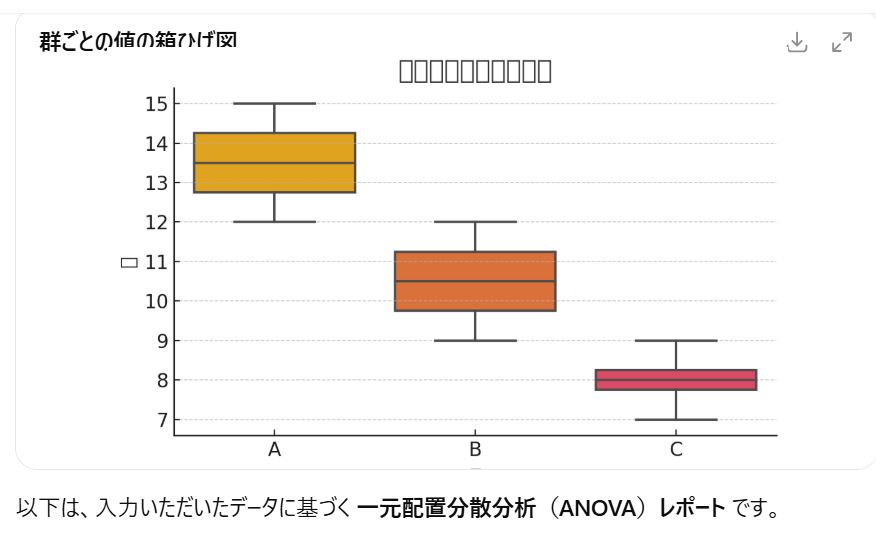
データ例:
-
グループA:12, 15, 14, 13
-
グループB:10, 11, 9, 12
-
グループC:8, 9, 7, 8
層別分析:
箱ひげ図でAが全体的に高く、Cが低いとわかる。
→ 「グループによって違いがありそう」と視覚的に判断。
分散分析:
F値 = 18.5、p値 = 0.001 なら
→ 「差は偶然ではない。グループ間で平均に有意差あり」と結論づけられる。
比較表
| 観点 | 層別分析 | 分散分析 |
|---|---|---|
| 例え | ルーペでデータを観察 | 顕微鏡で統計的に証明 |
| 性格 | 定性的・探索的 | 定量的・検証的 |
| 最終目的 | 問題点を見つける | 仮説を検証する |
実務的な流れ(QC的視点)
1️⃣ 層別分析で「違いがあるか」を確認
→ 人・機械・材料・方法・時間などで層別。
2️⃣ 分散分析で「その違いが有意か」を確認
→ 改善の優先順位や対策の裏付けを得る。
層別解析については下記の記事を参照 願いします。
関連記事:AI chatGPTで層別解析~層別化の活用事例【図解】

ChatGPTを活用した分散分析の具体的なやり方
分散分析の手順をChatGPTでガイド
ChatGPTを使った分散分析の基本手順は次のとおりです。
-
目的の設定:「どのグループに差があるのか?」を明確にする
-
データの準備:分析対象となるグループごとの数値を整理
-
ChatGPTに質問:「このデータで分散分析をしたい」と入力
-
結果の確認と解釈:p値(有意確率)を確認し、結論を導く
💡 例:プロンプト
ChatGPTは上記のような入力に対して、Pythonコードを自動生成し、結果の意味を自然言語で説明してくれます。
以下がChatGPTでの分散分析(ANOVA)の結果です。
📊 分析結果
-
F値(検定統計量):22.75
-
p値(有意確率):0.00030
🔍 解釈
-
一般に、有意水準を α = 0.05 とした場合、
p値 < 0.05 なので、帰無仮説(「3グループの平均に差がない」)は棄却されます。
つまり、グループ間に有意な平均値の差がある と判断されます。
🧩 平均値の比較
| グループ | データ | 平均 |
|---|---|---|
| A | 12, 15, 14, 13 | 13.5 |
| B | 10, 11, 9, 12 | 10.5 |
| C | 8, 9, 7, 8 | 8.0 |
💡 結論
ChatGPTによるPython分散分析の結果から、
「グループA、B、Cの平均値には有意な差がある」
と結論づけられます。
実務的には、この後に 多重比較(Tukey法など) を行うと、
どの組み合わせ間に差があるかをより明確に特定できます。
必要なデータの準備とクリーニング
分散分析において最も重要なのは、「適切なデータを用意すること」です。
データに欠損値や外れ値があると、結果が歪む恐れがあります。
ChatGPTを使えば、データのチェックポイントを自動で整理できます。
💬 例:
「このデータを分散分析に使う前に確認すべき点を教えて」
と聞くと、以下のような出力が得られます。
このようにChatGPTが前処理のチェックリストを提示してくれるため、初心者でも安心です。
効果的なプロンプトの作成方法
ChatGPTを活用する上での鍵は「プロンプト設計」です。
的確な指示を与えることで、より精度の高い結果を得ることができます。
💡 良い例
「3つの販売チャネルの売上データを比較して、どのチャネルが最も効果的か分散分析で検証して」
⚠️ 悪い例
「売上の差を調べて」→ 目的や手法が曖昧で、結果が抽象的になる。
ChatGPTは明確な指示を好みます。
プロンプトの中に「目的」「データ形式」「希望する出力(グラフ・解釈)」を含めましょう。
分析結果の解釈とレポート作成
ChatGPTが出力する分散分析の結果は、統計ソフト同様に「p値」や「F値」を含みます。
しかし初心者がそれを見ても、「結局どう判断すればいいの?」と迷うことが多いです。
ChatGPTなら、以下のように解釈を補ってくれます。
💬 例:
「p値が0.03なので、95%の信頼水準で有意な差があるといえます。
グループAとBの間で平均値に統計的な違いがある可能性があります。」
🧮 1. F値とは?
グループ間の違いの大きさを表す数値です。
たとえば──
-
グループA・B・Cの平均がほとんど同じなら「F値」は小さくなります。
-
逆に、平均に大きな差があれば「F値」は大きくなります。
👉 F値が大きいほど、「グループ間に差がありそうだ」と考えます。
F値そのものに「何点以上なら合格!」という絶対基準はありません。
実際には「自由度に応じた臨界値(クリティカルバリュー)」と比較して判断します。
F分布表による臨界値の求め方
分散分析では、
-
グループ間の自由度(df₁)=「グループ数 − 1」
-
グループ内の自由度(df₂)=「全データ数 − グループ数」
で計算します。
事例:
-
グループ数 = 3
-
各グループ4個 → 合計12個の場合
-
df₁(群間)= 3 − 1 = 2
-
df₂(群内)= 12 − 3 = 9
有意水準5%のときの基準(F分布表より)
| 有意水準(α) | df₁ | df₂ | 臨界値(Fの基準) |
|---|---|---|---|
| 0.05 | 2 | 9 | 約4.26 |
| 0.01 | 2 | 9 | 約8.02 |
ざっくり感覚的な目安(初心者向け)
| F値の範囲 | 感覚的な意味 |
|---|---|
| 0~1 | グループ間の差はほぼない |
| 1~4 | わずかな差(偶然かもしれない) |
| 4~10 | 明確な差(要確認) |
| 10以上 | かなり大きな差(有意の可能性高い) |
📉 2. p値とは?
「その差が たまたま起きた 可能性」を表す数値です。
-
p値が 小さい(例:0.05未満) → 偶然ではなさそう
-
p値が 大きい(例:0.1以上) → 偶然の可能性が高い
👉 p値が0.05より小さい ときは、
「グループ間に統計的な差がある」と判断します。
さらに、ChatGPTに「この結果を社内レポート形式にまとめて」と指示すれば、
グラフ付きの報告文まで自動生成可能です。
分散分析レポート作成 カスタムGPT 紹介
ChatGPTで分散分析を簡単に実行できるカスタムGPTです。
ユーザーから提供されたデータを基に、一元配置分散分析を実行し、わかりやすく解釈を加えた社内レポートをMarkdown形式で作成できます。
分散分析レポート作成 GPT
ChatGPTで分散分析を行うツールや機能の比較
一般的なデータ分析ツールとの比較
分散分析は、Excel・R・Pythonなどのソフトウェアでも実施可能です。
しかし、これらのツールにはそれぞれ習熟コストが存在します。
| ツール名 | 特徴 | 学習コスト | ChatGPTとの違い |
|---|---|---|---|
| Excel | 手軽に使えるが統計関数の理解が必要 | 低〜中 | 関数入力が必要 |
| R | 統計分析に特化 | 高 | コード知識必須 |
| Python | 分析+機械学習に対応 | 中〜高 | コードとライブラリ理解が必要 |
| ChatGPT | 会話形式で手順・コード・解釈を自動生成 | 低 | 対話で完結 |
ChatGPTの性能と精度の評価
ChatGPT(特にGPT-4・GPT-5以降)は、分散分析の手法理解・コード生成・結果説明において非常に高精度です。
ただし、数値計算自体は内部でシミュレーションしている場合があり、厳密な統計ソフトの再現性とは異なることがあります。
他の生成AIとの違いや特徴
分散分析に活用できる生成AIはChatGPT以外にも存在します。
たとえば、Google Gemini や Anthropic Claude などです。
しかし、ChatGPTには以下の明確な優位点があります。
一方、他AIは英語中心・説明が抽象的な場合が多く、初心者にはやや難解です。
分散分析を「理解」から「実践」まで学ぶには、ChatGPTが最も適しています。
実践!成功事例の紹介とその理由
企業の成功事例から学ぶ分散分析の活用
事例①:広告効果測定の効率化(マーケティング部)
ある企業では、3種類のバナー広告を用いてクリック率を比較するためにChatGPTで分散分析を実施しました。
結果、ChatGPTのサポートで次のような流れが自動化されました。
-
データ入力方法の提示
-
分散分析のコード生成(Python)
-
p値の解釈とグラフ作成
-
結果の文章化レポート
💬 担当者の声:
「統計知識がゼロでも、ChatGPTに聞きながら分析設計できた。
分析結果を上司向け資料にすぐ反映できたのが便利でした。」
事例②:製造業での工程改善
製造ラインにおける「作業者A・B・Cによる製品寸法のばらつき」をChatGPTで解析。
分散分析の結果、作業者Bの工程で有意な差が見られ、原因となる工程を特定できました。
ChatGPTは、結果の原因仮説まで提案してくれたため、改善策立案が迅速に進みました。
事例③:教育研修の効果測定
人事部門では、3種類の研修プログラムの前後テスト結果を分散分析。
ChatGPTが自動で前処理と分析を支援し、「研修Cが最も成果を出している」と特定しました。
自社での実践結果の共有
ChatGPTを導入した企業では、データ活用文化の醸成という副次的な効果も得られています。
社員が自然言語でAIに質問しながら分析を行うことで、「統計=身近な業務スキル」になりつつあります。
長期的な業務改善への影響
分散分析の理解をChatGPTを通じて広めることは、次のような中長期的メリットをもたらします。
-
意思決定のスピードアップ
-
部門間での共通データ言語の形成
-
AIと人間の協働による生産性向上
これらは単なる業務効率化を超え、企業文化の変革につながります。
分散分析における注意点とリスク
データの取り扱いに関する注意点
ChatGPTに分析用データを入力する際は、機密情報を含まない形に加工することが重要です。
実データをそのまま貼り付けるのではなく、「サンプル化」「匿名化」して利用します。
💬 ChatGPTへの質問例
「この売上データを匿名化して分析用に整形して」
→ ChatGPTが自動で「個人名・顧客番号」を削除した仮想データを生成
リスク管理と対策方法
AI分析のリスクは以下の3点に整理できます。
| リスク | 内容 | 対策 |
|---|---|---|
| データ漏洩 | 実データを入力 | 匿名化・社内専用GPT利用 |
| 解釈ミス | 統計的誤りの放置 | 結果の二重確認 |
| 過信 | ChatGPTの回答を鵜呑みにする | 補助ツールとして利用 |
限界や制限性の理解
ChatGPTは強力な分析補助ツールですが、次のような限界もあります。
-
複雑な階層分散分析(多要因ANOVA)は誤解釈の可能性あり
-
データの分布異常を自動検出する機能は限定的
-
AIは「数値の意味」を統計的に推定するが、真の因果関係までは断定できない
💬 ChatGPTを「万能な統計ソフト」として使うのではなく、「理解とサポートを得るアシスタント」として活用するのがベストです。
今後のChatGPTと分散分析の進化
最新技術の動向とビジネスへの影響
AI技術の発展により、ChatGPTは「文章生成」から「統計分析支援」へと進化しています。
2025年現在では、次のようなアップデートが実装されています。
-
データ解析プラグインの強化(CSV・Excel対応)
-
**コードインタープリタ(Python実行環境)**の精度向上
-
視覚的グラフ出力による直感的な結果理解
-
自動レポーティング機能の追加
これにより、ChatGPTは従来のBIツールやExcelを補完する存在になっています。
特に分散分析(ANOVA)は、経営判断・品質管理・人材評価など、あらゆる業務領域で応用可能です。
教育や社内研修への適用
ChatGPTを活用した分散分析の教育事例は、大学・企業研修の両方で増加しています。
AIを「学習支援者」として利用することで、従来の座学よりも実践的なスキル習得が可能になります。
💬 研修での活用例:
-
ChatGPTに「分散分析を実践形式で教えて」と指示
-
AIが自動でケーススタディを生成
-
受講者がAIと対話しながら分析を実施
-
結果を即時フィードバック
🎯 効果:学習者が「自分の言葉で統計を説明できる」レベルに成長。
このように、ChatGPTは教育分野でも「データリテラシー育成」の中心的存在となりつつあります。
持続可能なデータ分析の未来
分散分析をAIと共に行う流れは、今後さらに広がります。
特に注目されているのは、「説明可能なAI(XAI)」の分野です。
XAI(Explainable AI)を組み合わせることで、ChatGPTが単に結果を出すだけでなく、
「なぜその結果になったのか」を透明に説明できるようになります。
また、オープンデータとAI分析を組み合わせることで、社会課題の可視化・政策判断にも活用可能です。
まとめ:ChatGPTを使った分散分析の全体像
学びのポイントと今後のステップ
この記事で学んだポイントを整理します👇
自社での導入プランの設計法
ChatGPTを業務に導入する際のステップは以下の通りです。
-
目的設定:「どんな意思決定に分散分析を使うか」明確化
-
データ整備:社内のデータ形式を統一
-
ChatGPT活用研修:分析担当者にAI操作を習熟させる
-
試験導入→本格運用:小規模データでテスト後、全社展開
💬 導入時には「ChatGPT Enterprise」や「社内専用GPT」など、
セキュリティ面を強化したバージョンの利用を検討しましょう。
理解を深めるための参考文献
📚 おすすめのリソース:
-
書籍:分散分析超入門
-
書籍:実験計画と分散分析のはなし
🔍 まとめ
「ChatGPTは単なるツールではなく、“共に学ぶパートナー”です。 分散分析を通じて、数字の裏にある意味を一緒に考えるAIとして、 日々の業務改善や意思決定にぜひ役立ててください。」
関連記事:ChatGPTで分散分析・・寸法バラつきとの闘い

🚀 次に読むおすすめ記事
コメント